LangChain 1.0 and LangGraph 1.0 set the agent runtime standard
With the 1.0 cycle for LangChain and LangGraph, stateful graphs, guardrails, human review, and deep observability move agents from dazzling demos to dependable enterprise systems. Here is what changes and how to adopt it now.

The 1.0 moment that moves agents from demo to dependable
This fall, the LangChain team kicked off the 1.0 release cycle for both LangChain and LangGraph. The alpha milestone arrived in early September 2025 with a clear promise for stability and a late October target for general availability. It is more than a version bump. It is the clearest signal yet that the agent runtime is crystallizing into a durable layer for production. For readers who only track big-bang model releases, this may feel quieter, but it changes the way teams ship. The 1.0 cycle tightens interfaces, promotes stateful graphs to first-class status, and puts guardrails, human review, and observability on the main path rather than as afterthoughts. See the official summary in the LangChain and LangGraph 1.0 alpha release.
Two practical details matter for teams planning the next quarter. First, LangGraph reaches 1.0 largely unchanged in surface area, which reduces migration risk for projects using 0.6.x. Second, LangChain tightens around a single agent abstraction built on LangGraph, prunes legacy patterns into a compatibility track, and standardizes message content through content blocks. Those moves focus the ecosystem on one runtime model and one way to make agents behave. For why this matters across platforms, revisit our chat is the new runtime thesis.
Why agent demos stall in production
Most stalled agent programs share the same symptoms, regardless of industry:
- The agent cannot remember what it did, so retries and resets lose context and cost money.
- The approval step happens in chat or a ticketing comment, not in the runtime, which leads to forked logic and shadow decisions.
- The system’s behavior is hard to explain. There is no stepwise trace, so debugging means scrolling logs and guessing.
- The prototype grew inside an integrated development environment. The clever loop that looked great at the hackathon now sprawls across callbacks, background jobs, and brittle glue code.
These are symptoms of missing runtime features, not missing prompts. A graph runtime treats an agent like a workflow with typed state, edges, and checkpoints, not like an infinite chat loop.
What the 1.0 agent runtime actually adds
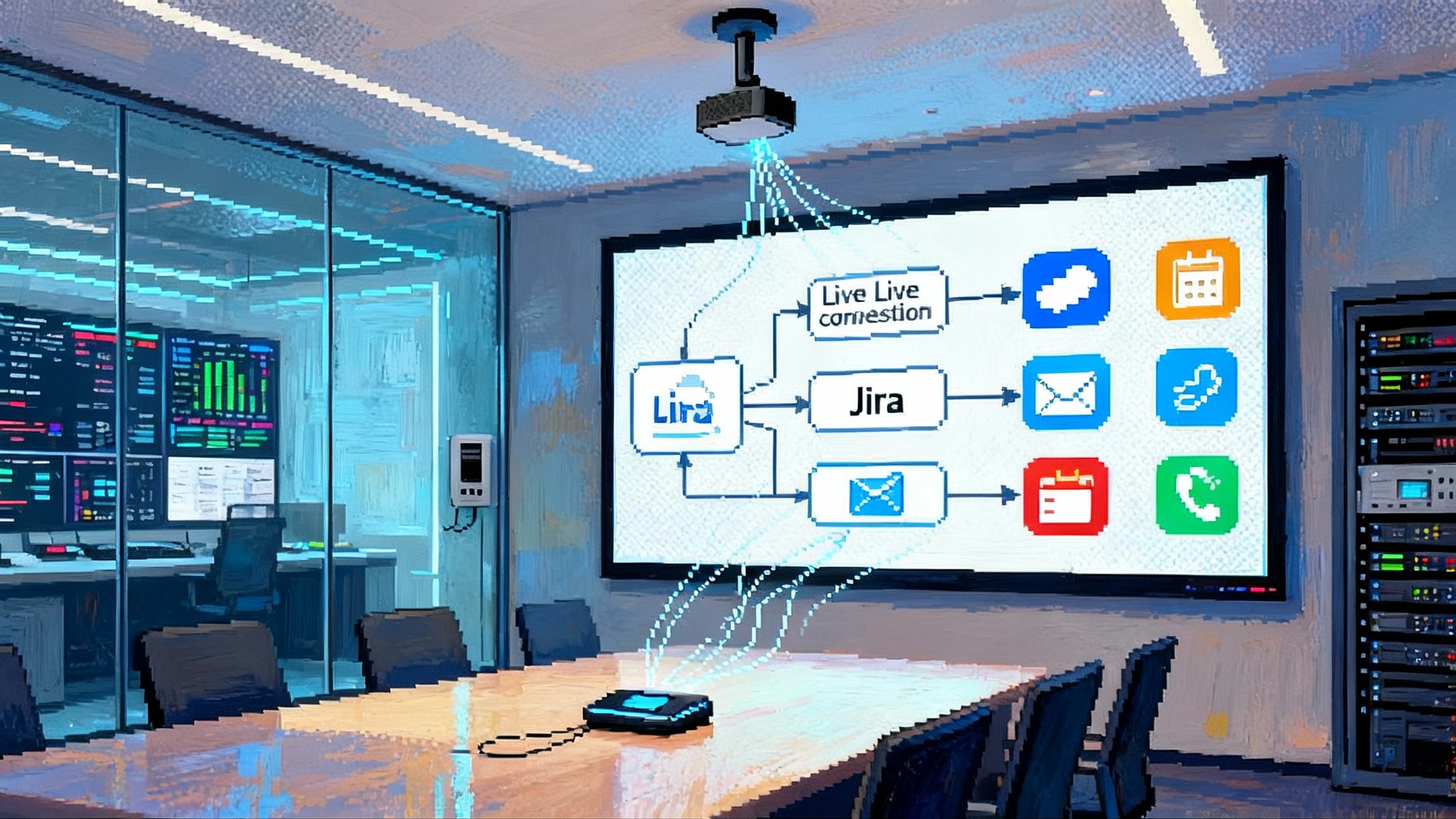
Think of LangGraph as a mission control timeline. Each node is a role with a job to do. Each edge is a decision about who works next. The state is a ledger that records what happened and what changed. With 1.0, four capabilities move from nice-to-have to required:
1) Durable state with checkpoints
- What it is: The runtime persists agent state after every node. You can resume, replay, or branch from any checkpoint using a thread identifier. In development you can use an in-memory saver. In production you plug in Postgres or Redis.
- Why it matters: You never lose context. Long-running tasks survive restarts. If a legal reviewer asks why the agent sent a message, you can replay the exact path that led there, including model calls and tool invocations.
2) Human in the loop as a first-class primitive
- What it is: Interrupts that pause the graph and wait for structured human input, then resume exactly where you placed the breakpoint. This brings approvals, edit suggestions, and policy checks into the same execution fabric as the agent itself. See how to enable human intervention in LangGraph.
- Why it matters: Instead of copying output to a chat for ad hoc review, risk owners can approve or revise within the graph, with audit trails and time travel preserved.
3) Guardrails through structure and policy hooks
- What it is: The 1.0 stack bakes in structured output strategies. You declare schemas in code, the agent returns typed data through provider-native mechanisms when available, and falls back to tool-calling strategies with validation when not. Policy hooks and middleware can whitelist tools, redact fields, and enforce limits across nodes.
- Why it matters: You reduce glue code and cut the class of production bugs caused by brittle string parsing. You also shift alignment work from prompt phrasing to explicit structure.
4) Deep observability and evaluation
- What it is: First-party tracing and evaluation through LangSmith. Every step shows up in a timeline with inputs, outputs, tool calls, costs, and model metadata. You can log production traces to datasets and use evaluators and human annotations to guard releases.
- Why it matters: You get a feedback loop that looks like software engineering rather than speculation. Regressions are caught in continuous integration before they reach customers.
This is what an agent runtime looks like when it grows up. It is less about a clever loop and more about a system that survives reality.
IDE-bound coding agents versus runtime agents
Coding agents embedded in editors are useful. They speed up refactors, suggest tests, and scaffold files. In many shops they are beloved power tools. But they are not a runtime. Here are the differences that matter:
- Ownership of state: IDE agents keep context inside an editor session. Runtime agents keep durable state in a checkpoint store with thread identifiers. That makes rollback, replay, and audit possible.
- System integration: IDE agents act on files and local commands. Runtime agents call tools behind policies and identities, coordinate multistep workflows, and report back.
- Oversight: IDE agents rely on the developer to accept or reject changes. Runtime agents make approvals part of the execution timeline and capture who did what and why.
- Quality loop: IDE agents do not ship with trace-level observability or evaluator pipelines. Runtime agents do, so teams can tune quality with data.
In short, IDE agents accelerate individuals. Runtime agents coordinate systems. The 1.0 releases are about the latter.
A concrete example: claims automation that you can trust
Imagine an insurance claim assistant that triages email, checks policy coverage, requests documents, and drafts a settlement offer.
- The graph begins with a triage node that classifies the email and attaches a confidence score. The state ledger stores the classification, the sender, and a claim identifier.
- If confidence is below a threshold, the graph interrupts and routes to a human adjuster for a thirty second label. The adjuster’s response flows back through the same state key the model would have written, with a reason code attached.
- A document collection node issues a signed link and waits for uploads. The state captures receipt timestamps and a hash for each file.
- A policy rules node runs a retrieval augmented generation check against policy text and a rules table. The agent’s output must conform to a simple schema with fields like coverage_amount and required_exclusions. If validation fails, the node retries or raises a policy error for human review.
- An offer node drafts the settlement and streams token by token for the user interface. The final checkpoint stores the offer, the rationale, and the document list.
Two traits make this production ready. First, you can replay the entire decision path if a regulator asks how a number was computed. Second, any approval or edit happens inside the same graph so your audit trail is complete. These are not features an editor plugin will give you.
A practical migration path from prototype to 1.0
Treat migration as a series of small, controlled steps:
- Inventory the prototype
- List model calls, tool invocations, and external systems. Pull a week of logs if you have them. Mark steps that already require a human decision. Decide what state you need to persist across steps.
- Draw the graph you already have
- Sketch nodes and edges. If you cannot draw it, you will not be able to operate it. Start with one happy path and two high-frequency exceptions.
- Define the state
- Create a typed state object with only the fields you need. Decide on stable keys. Name one field for the final output. Keep it boring, like an invoice or a claim object.
- Add a checkpointer
- In development use an in-memory saver to iterate. For production pick Postgres with a managed service or Redis for higher throughput. Configure thread identifiers so every run has a durable identity.
- Place the first interrupt
- Put an interrupt at the first high-risk decision, usually a tool call with side effects or a low-confidence classification. Resume the graph with structured human input. Use this to socialize the new workflow with risk and operations teams.
- Wrap outputs with structure
- Replace string parsing with schema-validated outputs. Start with the final output type. Then backfill upstream nodes where structure adds the most reliability.
- Turn on tracing and basic evals
- Enable tracing with environment variables, then create a small dataset from production traces. Add one evaluator that checks a simple business rule. Expand later with human annotation queues.
- Stage, gate, and roll out
- Add version tags to runs and model prompts. Put a score threshold in continuous integration that must hold before a promotion. Roll out behind a feature flag. Decide in advance what you consider a rollback event.
For how control planes evolve around these practices, see how agent control planes go mainstream.
What this unlocks for enterprises right now
- Cross-vendor, multimodel stacks: With standardized message content, you can mix providers and toggle capabilities like native structured output without changing your graph. That reduces switching costs and contract risk as the model landscape shifts.
- Risk and compliance alignment: Interrupts and typed outputs make policy embedding practical. You can represent approvals, escrows, and sanctions checks as graph nodes with clear owners. This dovetails with stronger identity and policy controls.
- Efficiency: Durable state eliminates redundant work. You only reprompt when a node needs it. Checkpoints are a budget control lever.
- Team clarity: Traces replace guesswork with a shared picture of what the agent did. Engineers, operators, and auditors see the same timeline.
Where consolidation goes over the next 12 months
Agent orchestration will not stay fragmented. The likely end state is a small set of runtimes, each with its own gravity:
- Open source graph runtimes led by LangGraph. Expect continued adoption because it gives teams low-level control with battle-tested patterns and because the 1.0 cycle aims for stability with minimal breaking changes.
- Cloud-native agent services from major providers. These will be attractive for teams already invested in one vendor’s identity, data, and compute. They will close gaps in guardrails and governance and serve as managed alternatives for simpler workflows.
- Niche runtimes for vertical needs. For example, safety-critical or regulated domains may want additional formal verification or signed audit trails baked in.
What consolidates is not the idea of an agent but the contract of a runtime: stateful graphs, structured outputs, human approval, and observability.
How to tell if your prototype is ready for 1.0
Use this scorecard to decide if you are ready to migrate:
- Can you redraw your system as a small graph of nodes and edges that a new hire can understand in five minutes?
- Does each node write exactly the state it owns, with a clear schema and a single output field for downstream steps?
- Can you pause for human approval where risk is highest, record the decision, and resume without hacks?
- Do you have a trace for a typical run that shows model calls, tool calls, costs, and latency, and can you add that trace to a dataset for evaluation?
- If a model or provider changes terms next quarter, can you switch without rewriting your graph?
If you cannot answer yes to four of five, the migration steps above are your plan. For a broader market view, revisit the chat is the new runtime thesis.
The bottom line
The 1.0 release cycle for LangChain and LangGraph is a turning point for agent systems. It standardizes runtime ideas that have quietly proven themselves in the field and brings them into a single, durable contract. In practical terms, that means less glue code, fewer late night regressions, and a runtime that product, risk, and engineering can all point at with confidence. The demos were fun. The dependable agent era will be better.