Ethereum’s slashing wave: DVT and restaking risk revealed
A rare September 10, 2025 slashing of about 40 Ethereum validators tied to SSV-powered clusters is a wake-up call. We break down how DVT and live EigenLayer slashing reshape correlated risk and give operators and LST holders a practical playbook to reduce exposure now.
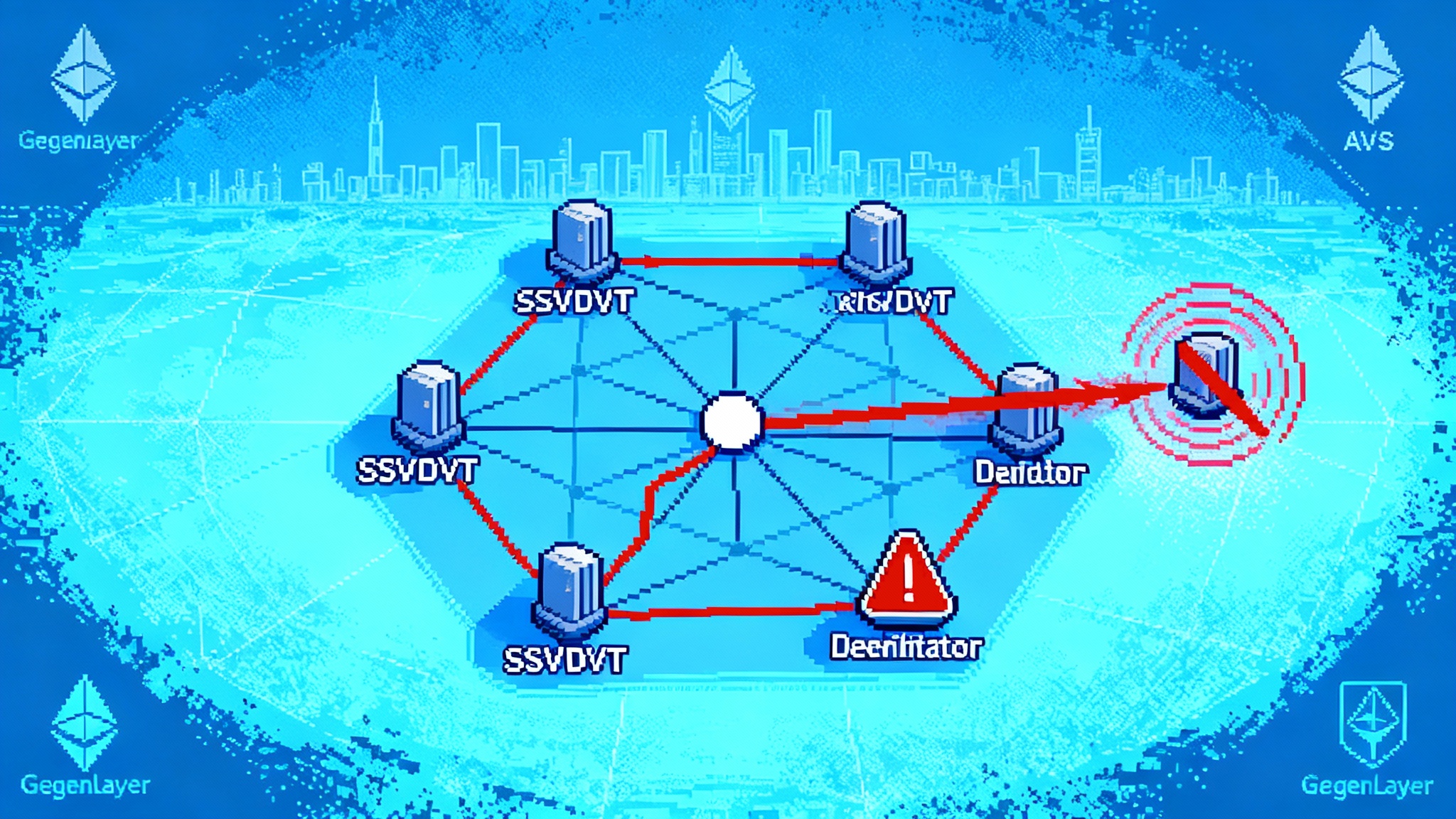
The September 10 wake-up call
On September 10, 2025, Ethereum saw a rare slashing wave that hit two separate incidents within hours. One validator was penalized first, followed by a correlated hit to a 39-validator cluster operated through SSV-powered distributed validator technology. The pattern was not a protocol bug. It was an operational lapse that left the same validator keys active in more than one environment, creating duplicate duties and triggering slashing. SSV’s own investigation details a clear sequence and takeaway: DVT reduces many risks, but it cannot save you from key reuse and parallel instances outside the cluster’s control, which can still cause double-signing. See the post-mortem for the full timeline and conclusions in the SSV post-mortem details.
The number matters less than the mechanism. Roughly 40 validators slashed in a burst shows how correlated penalties can arise when the same operational mistake propagates across a clustered setup. It is a reminder that the hardest problems in staking are usually operational, not cryptographic.
DVT reduces single-operator risk but introduces new surfaces
Distributed validator technology spreads signing responsibility across multiple operators using threshold cryptography and fault-tolerant coordination. Done right, it hardens uptime, removes single-operator keys as a point of failure, and makes censorship or unilateral misbehavior much harder. That is why LST protocols and institutions increasingly lean on DVT to diversify operator sets and reduce idiosyncratic risk.
But DVT is not a free lunch. It reframes operational risk.
- Key reuse outside the cluster: If validator keys or their derivatives are present in any parallel setup, the cluster’s guarantees are defeated. Parallel instances can double-sign despite DVT’s internal safety.
- Split-brain failover: Poorly tested disaster recovery that spins up redundant infrastructure while the original cluster remains live can create dueling instances.
- Slashing protection drift: Slashing protection databases are only as good as their hygiene. If you migrate or fail over without merging and validating histories, you risk violating attestations or proposals on restart.
- Correlated operator actions: When multiple validators share the same runbooks, cloud images, or automation, an error can propagate across many keys at once. DVT mitigates single-node faults, not homogeneous mistakes replicated at scale.
The September incidents highlight that clustering lowers some tails but can sharpen others. The goal is not to abandon DVT. It is to operate it with the same key isolation, change control, and forensic discipline you would demand in a payments environment.
Restaking now has hard edges
Restaking supercharges capital efficiency by letting validators opt into securing additional services in exchange for more rewards. With slashing now live on EigenLayer, those extra rewards come with enforceable penalties. EigenLayer’s rollout formalizes that operators and stakers are opt-in subject to AVS-level conditions, with new mechanics like unique stake allocation designed to compartmentalize exposure so one AVS cannot slash stake reserved for another. Review what is changing in Slashing is now live.
That is critical progress, but the combined landscape still creates new correlated-risk surfaces:
- Duty coupling: Restaked operators may run additional software stacks that introduce synchronized failure modes, especially if multiple AVSs share dependencies or push updates on similar cadences.
- Slashing condition complexity: AVSs can craft heterogeneous conditions. Operators that overcommit without strict mapping of conditions to their infrastructure runbook may trip conflicting rules across services.
- Operational blast radius: A migration or failover mistake similar to September’s incident could now cascade across native validator duties and multiple AVS processes if keys, stake allocations, or operator sets are not isolated in practice.
- Liquidity reflexivity: If a correlated slash touches large pools of delegated stake or popular liquid staking tokens, the resulting NAV impact or redemption pressure can feed back into operator behavior during incidents.
Unique stake allocation and operator sets are meaningful mitigations, but they only deliver safety if operators architect for risk compartments in a way their people and tooling can actually enforce.
What the slashing revealed about correlated risk
Consider how the September 10 event unfolded:
- The same validator identity effectively existed in more than one environment. A maintenance action spun up parallel duties outside the DVT cluster.
- DVT’s internal safety was irrelevant once the same key appeared elsewhere. Threshold coordination cannot arbitrate with unknown external instances.
- The second wave showed how a shared runbook or shared operator responsibility can amplify a mistake into dozens of slashes.
Now transpose that mental model onto restaking:
- A single operator might secure Ethereum consensus and multiple AVSs. If a change window introduces a split-brain across one component, do all components fail gracefully, or do some continue to sign old views and others new ones?
- If slashing protection databases are AVS-specific and tracked separately from consensus, does your team have a reliable way to merge, validate, and restore them under pressure?
- Do you have technical guardrails that prevent a validator identity from coming up in any environment that lacks the correct slashing protection state for every system it secures?
The path from one mistake to many penalties is shorter than it looks if you have not rehearsed these interactions.
A playbook operators can adopt now
You can meaningfully reduce correlated slashing risk with process, not just code. Start here.
1) Key isolation and environment controls
- Single tenancy for validator identities: A validator key must exist in exactly one controlled runtime. Enforce this with an HSM or enclave that will not sign unless the environment is attested and unique.
- No parallel cold starts: Implement hard interlocks that block starting any validator process if a heartbeat from the primary is active. Use mutually authenticated health checks across operators in a cluster.
- Secrets governance: Inventory every place a secret can live. Eliminate ad hoc backups and developer laptops. Use short-lived, audited access with break-glass procedures that require dual control.
2) Slashing-protection hygiene
- Treat slashing protection as a regulated dataset: change-controlled, backed up, and tested with restores. Use read-only mounts in production to prevent accidental corruption.
- Use the EIP-3076 interchange format for exports and merges. Validate that merges resolve conflicts deterministically before production restores.
- Bake slashing-protection checks into preflight scripts so a node will refuse to start if the local database is older than the latest known checkpoint.
3) Migration and failover runbooks
- Write a one-page cutover plan per cluster with an irreversible kill switch. Prefer terminating the old environment first, then bring up the new one only after independent confirmation that the old is dead.
- Rehearse in a staging environment with realistic timings. Timebox each step and record the expected logs so on-call can match reality under stress.
- Add a final sanity check: before enabling duties, confirm a recent signed message from the expected environment and that all peers reflect the same fork choice.
4) Change management and observability
- Tight maintenance windows: treat upgrades and cloud changes like surgical procedures with sign-off, rollbacks, and blast-radius estimates.
- Multi-layer alerts: validator duty anomalies, slashable offenses, missed attestations, duplicate signing attempts, and AVS-specific condition monitors.
- Out-of-band comms: ensure operator teams and any custody partners share an incident channel that survives a cloud outage.
5) DVT-specific guardrails
- One cluster instance per validator identity, enforced by design. If you rely on a coordinator or registry, make it authoritative and deny duty unless membership is current.
- Heterogeneous operators and clients: mix client implementations, clouds, and regions to avoid synchronized failure. Diversity is not a slogan; it is an anti-correlation control.
- Quorum-aware shutdown: when the cluster loses a threshold, prefer halting duties over attempting degraded service that risks equivocation.
6) Restaking-specific controls
- Map every slashing condition to concrete monitors and SLOs. If you cannot observe it, you cannot safely accept it.
- Use unique stake allocation to compartmentalize AVS exposure. Do not let the same stake be slashable by more than one service.
- Separate operator sets for different risk profiles. Keep the most experimental AVSs isolated from your bread-and-butter consensus operations.
- Maintain a consolidated risk ledger that shows, per validator identity, the full set of slashable conditions across consensus and all AVSs.
Implications for LST holders and custodians
Liquid staking tokens abstract away validator operations, but they cannot abstract away risk. Here is what the September event and live restaking penalties imply.
- NAV sensitivity: A correlated slashing event dilutes the pool and can pressure secondary market pricing. Even small per-validator penalties, when multiplied across a cluster, can dent yields and net asset value.
- Policy transparency: LST protocols should publish how they use DVT, how many operators share similar runbooks, and what migration practices look like. Vague assurances about decentralization are not enough.
- Redemption and liquidity planning: If a large LST suffers a correlated slash, redemptions may spike. Protocols need buffers, orderly exit policies, and market-maker lines to reduce reflexive discounts.
- Custodian coordination: Institutional custodians that delegate to operators must insist on key isolation attestations, slashing-protection procedures, and change windows. Contracts should include representations and warranties on DVT and restaking practices, with audit rights and incident reporting timelines.
- Insurance and reserves: Some LSTs or custodians may choose to self-insure or partner with specialized underwriters for correlated slashing. If you do, align policy triggers with measurable operator behaviors, not vague negligence clauses.
Shifts in payment and market rails can also shape liquidity backstops. For example, the GENIUS Act reshapes stablecoin rules, and evolving venue concentration such as a potential crypto derivatives center of gravity can amplify reflexivity during stress.
What to watch as institutions and ETFs scale into year-end
Institutional staking is scaling and spot ETH exposure via ETFs is maturing. Even if some large vehicles do not stake today, the market is already pricing the possibility that more institutional capital will participate over time, especially as SEC fast-tracks crypto ETFs.
- DVT standardization: Expect clearer standards for cluster orchestration, slashing-protection merges, and client diversity. Look for public self-assessments from major LSTs and custodians.
- Restaking segmentation: How effectively operators use unique stake allocation and operator sets will determine whether restaking risk is compartmentalized or pooled by accident.
- Client and infra diversity metrics: Transparent dashboards that show client mix, cloud distribution, and region spread across operator sets will become table stakes for institutional mandates.
- Incident post-mortems with evidence: The September post-mortem model is the right direction. Demand timelines, logs, and specific lessons, not just conclusions.
- AVS maturity curve: Not all AVSs are equal. Institutions will gravitate to those with clear slashing conditions, high-quality reference implementations, and proven rollback and recovery guidance.
- Regulated-custody controls: Look for formalization of SOC-type controls around slashing protection, key isolation attestations, and change management specific to DVT and restaking.
A concise checklist you can adopt this week
- Inventory validator identities and where they can be started. Eliminate every shadow path.
- Export, merge, and verify slashing protection across all environments. Schedule periodic restore tests.
- Implement a heartbeat-based interlock that blocks parallel starts. Test it.
- Write and rehearse a one-page migration runbook per cluster with an irreversible kill step.
- Map every restaking service to its slashing conditions, monitors, and on-call rotations. Use unique stake allocation to fence risk.
- Confirm your client and infra diversity. Move away from any single point of correlated failure.
- Establish an incident comms channel with your LST protocol or custodian counterparties.
The bottom line
DVT and restaking are not at odds with safer staking. They are tools that, when run with professional-grade ops, can reduce single-operator fragility while unlocking new services secured by Ethereum’s economic weight. The September 10 slashing wave was not a failure of DVT. It was a failure of operational boundaries around keys and migrations. With EigenLayer penalties now enforceable, the cost of sloppy change management just went up.
Treat keys as single-tenant. Treat slashing protection as critical data. Practice migrations until they are boring. Compartmentalize restaking with unique stake allocations and operator sets that match your risk appetite. If institutions and ETFs are going to scale staking exposure into year-end, the winners will be the operators who can prove, not promise, that they know how to keep one validator identity in one place at one time, every time.