Microsoft’s Agent Framework unifies the enterprise agent stack
Microsoft's Agent Framework public preview consolidates AutoGen and Semantic Kernel into a single production stack with typed workflows, durable memory, OpenTelemetry, and MCP support. See what it unlocks for enterprises and how to adopt it in 30 days.
The breakthrough that shifts agents from demo to durable
Microsoft quietly flipped an important switch. The Agent Framework, now in public preview, is positioned as the next generation of both Semantic Kernel and AutoGen, and it is built for production rather than proofs of concept. The official overview makes the intent explicit: a single, unified agent stack that enterprises can run in real systems, not just in hackathons or labs. See Microsoft's position in the Agent Framework overview.
This consolidation matters because it resolves the split brain that has confused teams for a year. One group prototyped complex multi agent flows in AutoGen. Another productized single agent skills in Semantic Kernel. Each had different abstractions, telemetry, and operational tradeoffs. The new framework gives a shared foundation with three practical unlocks: unified workflows, durable state, and first class observability, all while being friendly to the Model Context Protocol so tools and other agents can plug in without bespoke adapters. This fits a wider shift in agent runtimes, as seen when LangChain and LangGraph runtime standard stabilized core abstractions.
What is new in the public preview, in plain terms
Think of the framework as two layers you can use together or separately.
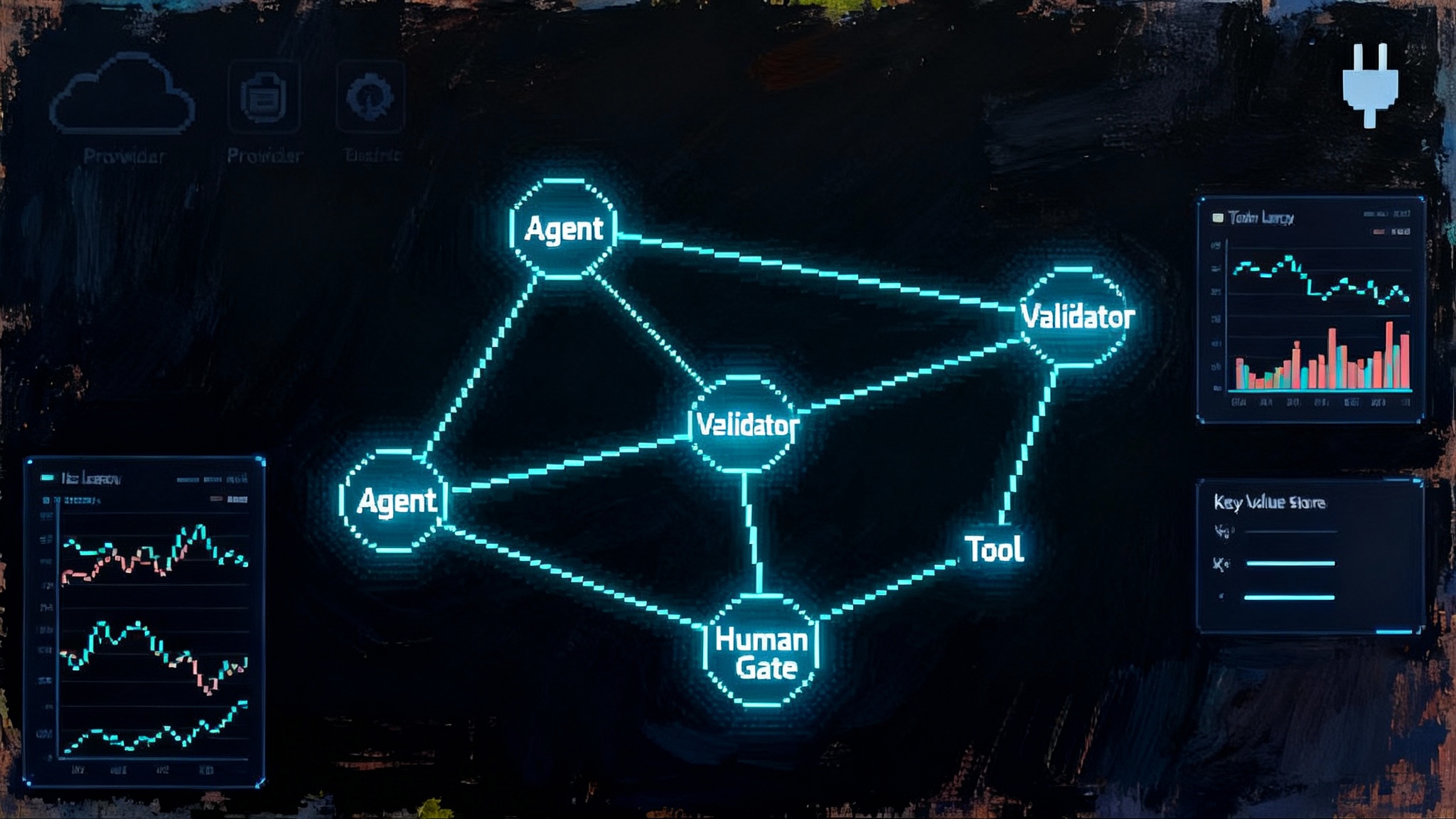
- Agents: The ChatAgent wraps a model client and tools. It handles multi turn interactions, function calling, and tool iteration until it can return a result.
- Workflows: A typed, data flow graph that connects agents, functions, and sub workflows with edges that carry specific message types. Workflows can pause for input, checkpoint state between supersteps, and resume reliably.
That pairing translates to three real enterprise benefits:
- Unified workflows you can reason about
Typed edges and explicit executors make control obvious. You can gate a tool call behind a validation function, route images and text along different paths, and add human approval steps that pause and then resume where you left off. Because the graph is data driven, you can test each executor in isolation and monitor the run as a series of events.
- Stateful memory you control
Threads and message stores give you choices. You can keep the entire conversation in memory for quick tests. You can persist messages to a store for audit and replay. You can also rely on workflow checkpointing to persist progress between supersteps, so a crash does not erase a two hour reconciliation task. The key is that state is explicit. That lowers cost by avoiding repeated re context and raises reliability by letting you resume rather than restart.
- Observability you can take to the SRE review
The framework emits OpenTelemetry traces, logs, and metrics that align with the GenAI semantic conventions. You can see spans for the chat client and the agent, track tool calls, capture token counts, and export everything to Azure Monitor or any OpenTelemetry backend. During development, a local dashboard gives you timing and event flow so you can spot loops, slow tools, and prompt blowups before they hit production.
A fourth unlock is ecosystem level: support for the Model Context Protocol. That means you can connect an agent to third party tools and services through standardized servers, and you can expose your own agent as a tool for other systems to call. It is the difference between building a walled garden and joining a city grid with streets and addresses. On Windows, native support for MCP and App Actions is arriving to help local agents interact with applications and the operating system, as covered in Windows backs MCP for local agents.
Why this is an inflection point for enterprises
For large teams, the cost of agent development is rarely the code. It is the glue. It is operational risk, auditability, and interoperability. The preview addresses those head on.
- Standard composition: A single agent type and a single workflow model simplify hiring, code reuse, and code reviews. Your reliability engineers do not have to learn two conventions just to read traces.
- Memory and checkpoints: Long running jobs no longer require custom retry wrappers or handmade state machines. Checkpoints give you roll forward recovery, which is the pattern most regulated industries prefer.
- Telemetry as a first principle: Out of the box traces and metrics let you define service level indicators on day one. You can attach cost budgets to spans, record tool failure rates, and set alerts on unbounded iterations.
- MCP friendliness: By aligning with a shared protocol for tools, you avoid writing custom shims for every new data source or action provider. That reduces time to integrate and makes portability a strategy rather than a promise.
In other words, the framework is not just an SDK. It is an operations story. That is the threshold that separates prototype from platform, and it aligns with how Agent control planes go mainstream across the enterprise stack.
How to migrate existing Semantic Kernel and AutoGen code
The best news is that migration is incremental. You can start with one agent or one team flow and expand from there. Microsoft's official guidance confirms that the framework is the successor to both, and it offers concrete mappings. When you are ready to make the leap, start with the Semantic Kernel migration guide.
Below is a practical plan, with quick code sketches to anchor the ideas.
Step 1: Replace plugins and function wrappers with simple tools
- In Semantic Kernel, you decorated methods with KernelFunction and wrapped them in plugins. In the new framework you register callable functions directly on the agent. Describe inputs and outputs in your docstrings or attributes so the framework can infer schemas.
Python example
from agent_framework import ChatAgent, ai_function
from agent_framework.openai import OpenAIChatClient
@ai_function("Get weather for a city")
def get_weather(city: str) -> str:
return "72F and sunny"
agent = ChatAgent(
name="ops-assistant",
chat_client=OpenAIChatClient(),
tools=[get_weather]
)
result = await agent.run("Weather in Seattle today?")
Step 2: Let the agent make the thread
- In Semantic Kernel and AutoGen you often created and passed threads explicitly. In the new framework the agent can create a new thread on request and can bind that thread to a persisted store for audit.
C# example
var agent = chatClient.CreateAIAgent(
name: "ops-assistant",
instructions: "Be concise and correct."
);
var thread = agent.GetNewThread(); // in-memory or backed by a store you configure
var reply = await agent.RunAsync("Summarize yesterday's deployment notes", thread);
Step 3: Map orchestration patterns to workflows
- AutoGen Teams and event broadcasts become typed data flows. Model each step as an executor. Connect edges by message type. Add a request or approval gate where you need a human in the loop. Enable checkpointing for long tasks.
Python example
from agent_framework import WorkflowBuilder, Executor, handler, FileCheckpointStorage
class Validate(Executor):
@handler
async def check(self, text: str, ctx):
if len(text) < 10:
await ctx.send_message(f"invalid:{text}")
else:
await ctx.send_message(text)
class Draft(Executor):
@handler
async def write(self, text: str, ctx):
await ctx.send_message(text + "
Drafted.")
storage = FileCheckpointStorage("./checkpoints")
workflow = (
WorkflowBuilder()
.set_start_executor(Validate())
.add_edge(Validate(), Draft())
.with_checkpointing(checkpoint_storage=storage)
.build()
)
Step 4: Turn on observability before you scale
- Set environment variables to enable OpenTelemetry, then export traces to Application Insights or your OpenTelemetry collector. Instrument cost per run in the same spans so you can spot loops, slow tools, and prompt blowups before they hit production.
C# sketch
using OpenTelemetry;
using OpenTelemetry.Trace;
using var tracerProvider = Sdk.CreateTracerProviderBuilder()
.AddSource("*Microsoft.Extensions.Agents*")
.AddOtlpExporter(o => o.Endpoint = new Uri("http://localhost:4317"))
.Build();
Step 5: Stage migration in rings
- Start with one agent or one workflow segment. Run it in shadow mode with traces on. Compare outputs and costs. Promote by ring when telemetry and acceptance tests are clean.
Architect multi agent apps for reliability and cost
There is no magic to reliable agents. There is discipline. Use the following patterns from day one.
- Control the iteration budget: Configure maximum tool iterations per run and alert when an agent reaches that ceiling. In traces, record a span attribute for final iteration count and tool call count, then set a warning threshold for unusual values.
- Gate tools with cheap validators: Before a tool call that can hit a rate limit or carry sensitive data, route the prompt through a rule based validator. Offload obvious rejects without burning tokens.
- Cache at the edge: Add a read through cache executor for expensive reference questions like policy lookups or long specifications. When an answer is stable for a day, your cache saves tokens and latency.
- Use checkpointing as your safety net: For long jobs like document processing or data reconciliation, save state between phases. If a downstream service fails, resume from the last superstep instead of replaying the entire run.
- Add human in the loop where the loss is real: Use workflow request and response gates for steps that carry legal or financial risk, for example closing a customer support case with refunds. Make the approval span explicit so you can measure response times and optimize staffing.
- Isolate high variance tools: Put risky tools behind their own executor. If they fail or time out, the span will show it clearly and your fallback path will stay readable.
- Track cost like an SLI: Emit tokens and billed cost as span metrics for both the chat client and the agent. Set budgets per workflow and per tenant. Alert when a run exceeds a standard deviation band rather than only a hard cap.
MCP friendly design that avoids lock in
The protocol is your seam. Treat MCP as the standard way to talk to external systems and as the standard way to expose your own capabilities. That yields three benefits.
- Replaceable providers: Because you integrate through MCP, you can swap an internal service or third party without rewriting the agent. Configuration and credentials change, the graph does not.
- Security as configuration: MCP connections can pass headers per run and can be limited to whitelisted servers. You can keep secrets in your existing vault and still present a clean tool to the agent.
- Two way interoperability: When you expose your agent as an MCP tool, other systems can orchestrate it without direct dependencies on your codebase. That makes platform adoption inside a large company much easier.
In Copilot Studio, MCP integration is already available so enterprise builders can broker data and actions into their copilots without custom adapters.
Position now for general availability without vendor lock in
The preview is stable enough to start real projects, and you can posture for general availability with a few design decisions.
- Program to interfaces, not vendors: Use the chat client abstraction rather than concrete providers in your business logic. Keep provider specifics in a thin factory.
- Keep hosted tools optional: Some hosted tools, such as code interpreter or web search, are convenient. If you need portability, structure your graph so that a hosted tool has a drop in local equivalent.
- Separate prompts from code: Put prompts in versioned files. Tag them in spans so you can correlate failures to a prompt revision. That helps with both portability and audit.
- Treat MCP servers as replaceable: Specify them in configuration with clear version pins. Add health checks. Prefer direct servers from the source vendor rather than unknown proxies.
- Make a portability test part of CI: For one or two critical workflows, run acceptance tests across two model providers weekly. Fail if outputs regress beyond a threshold. This forces your design to stay provider agnostic.
A 30 day adoption plan you can actually run
Week 1: Spike and trace
- Stand up a ChatAgent that performs a narrow task that already exists in production, for example summarizing incident timelines. Turn on OpenTelemetry. Capture token counts and latency.
- Define two simple tools and one MCP tool to prove the integration seam, for example a read only knowledge base lookup and a ticket search.
Week 2: Build a minimal workflow
- Add a workflow with three executors: a validator, an agent, and a formatter. Enable checkpointing. Run a load test with realistic concurrency. Compare the cost profile to your current approach.
Week 3: Add reliability rails
- Introduce a human approval gate on a high risk action. Add a fallback path for the most brittle tool. Start emitting cost and failure metrics as span attributes.
Week 4: Migrate one real use case
- Move a live path from Semantic Kernel or AutoGen to the new framework. Keep the old path in shadow for a week. If metrics and acceptance tests stay green, turn the old path off.
What could go wrong, and how to prevent it
- Runaway iterations: Set agent level iteration caps and add stop conditions in prompts. Monitor with alerts that trigger on sudden climbs in iteration counts.
- Silent tool drift: Tools change and schemas move. Guard with validators that check required fields and with contract tests in CI that exercise every tool once a day.
- Expensive context windows: If you stream entire histories into every call, you will pay for it. Use message stores with summarization, limit history by role, and move stable reference material into tools rather than prompts.
- Observability noise: Duplicated spans from both the chat client and the agent can cause confusion. Decide where to capture sensitive data and be consistent. Use sampling to keep volumes manageable in production.
The bottom line
Consolidation is rarely glamorous, but it is how platforms get built. With the Agent Framework public preview, Microsoft has given enterprises a coherent agent stack with the guardrails that production teams demand. The workflows make behavior explicit and testable. The state model makes long running work reliable. The telemetry turns agents from black boxes into services you can operate. MCP friendliness opens a path to a broader ecosystem instead of another silo. If you have been waiting for the moment when agents feel less like magic tricks and more like software, this is it. Start small, wire in observability, use MCP as your seam, and treat portability as a discipline rather than a slogan. When general availability lands, you will already be running agents that your developers, operators, and auditors can all understand and trust.