Zapier’s Multi‑Agent Pivot: No‑Code Becomes the New Runtime
Zapier reframed AI agents from chat helpers into an automation runtime. With pods, agent handoffs, and live knowledge, the center of gravity shifts to no-code orchestration for small and medium sized businesses.

Breaking: automation platforms are quietly becoming agent runtimes
On May 22, 2025, Zapier flipped the script on its agent strategy. Agents are no longer treated primarily as chat assistants. They are built and monitored as background automators that run work in the flow of your tools. Zapier’s help documentation spells it out clearly: the product moved from chat to automation and introduced pods plus a central activity view. That is the sound of an automation platform turning into an agent runtime. See the Zapier May 2025 update.
If you run a small or medium sized business, this is more than a branding tweak. Think of the old model as a helpful clerk at a counter. You ask a question and the clerk replies. The new model is an operations team in the back office that quietly moves orders, updates records, and pings you only when decisions are needed. This shift rhymes with how production-grade agent kits push agents from demos to dependable services.
What actually changed under the hood
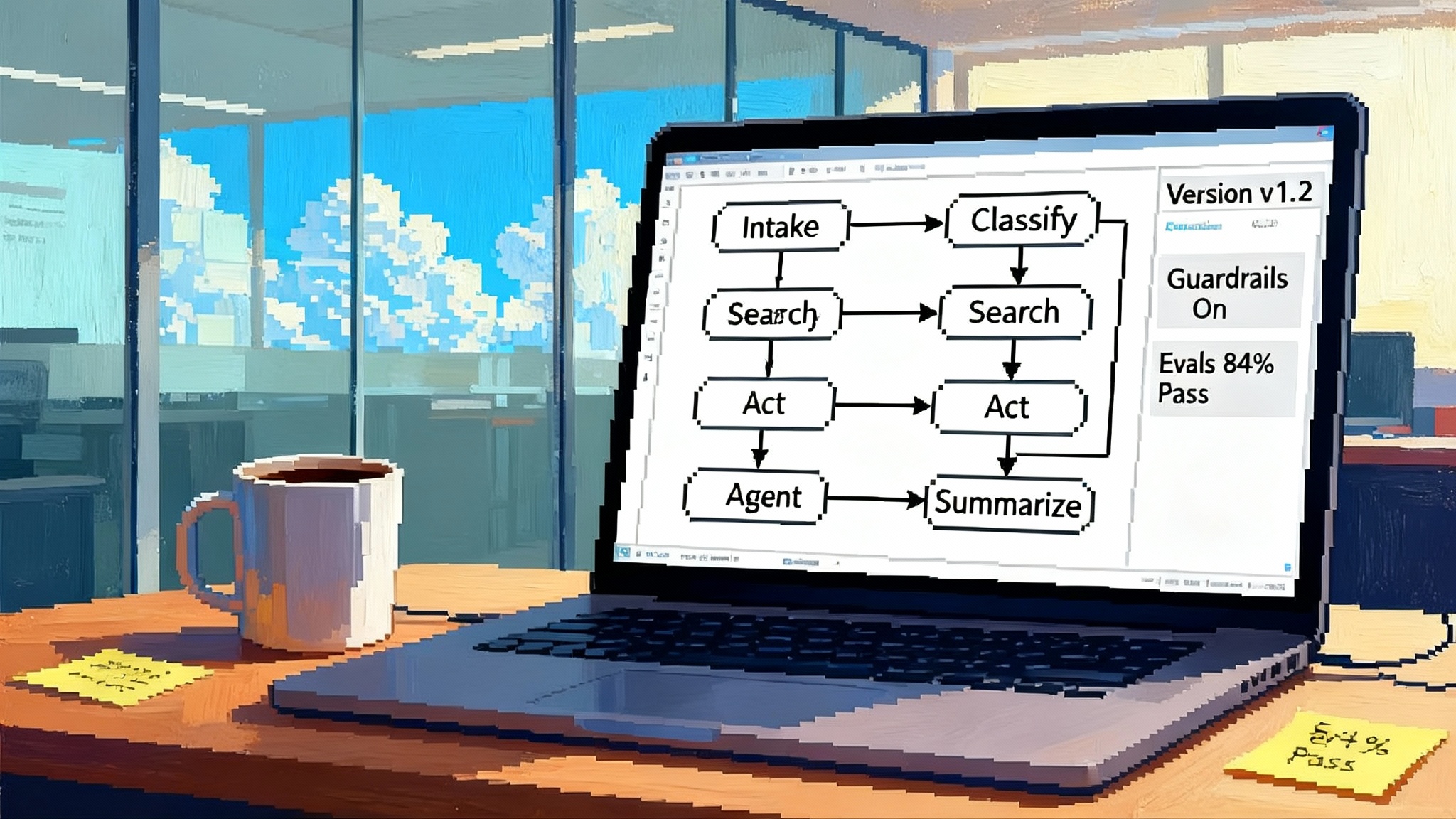
Zapier’s shift is not just packaging. Several structural pieces now point agents at production work:
- One agent, one job: agents are defined with narrow purpose and tools. That makes behavior easier to test and monitor.
- Pods: organize several purpose-built agents into a pod that shares a goal. Pods let you reason about a workflow at the team level rather than a single worker.
- All activity: a control tower that shows when agents succeeded, asked for input, or failed.
Together, these turn agents from conversations into orchestrated, observable processes. Narrow focus reduces drift. Grouping clarifies mental models. Central activity makes exceptions visible instead of surprising you later.
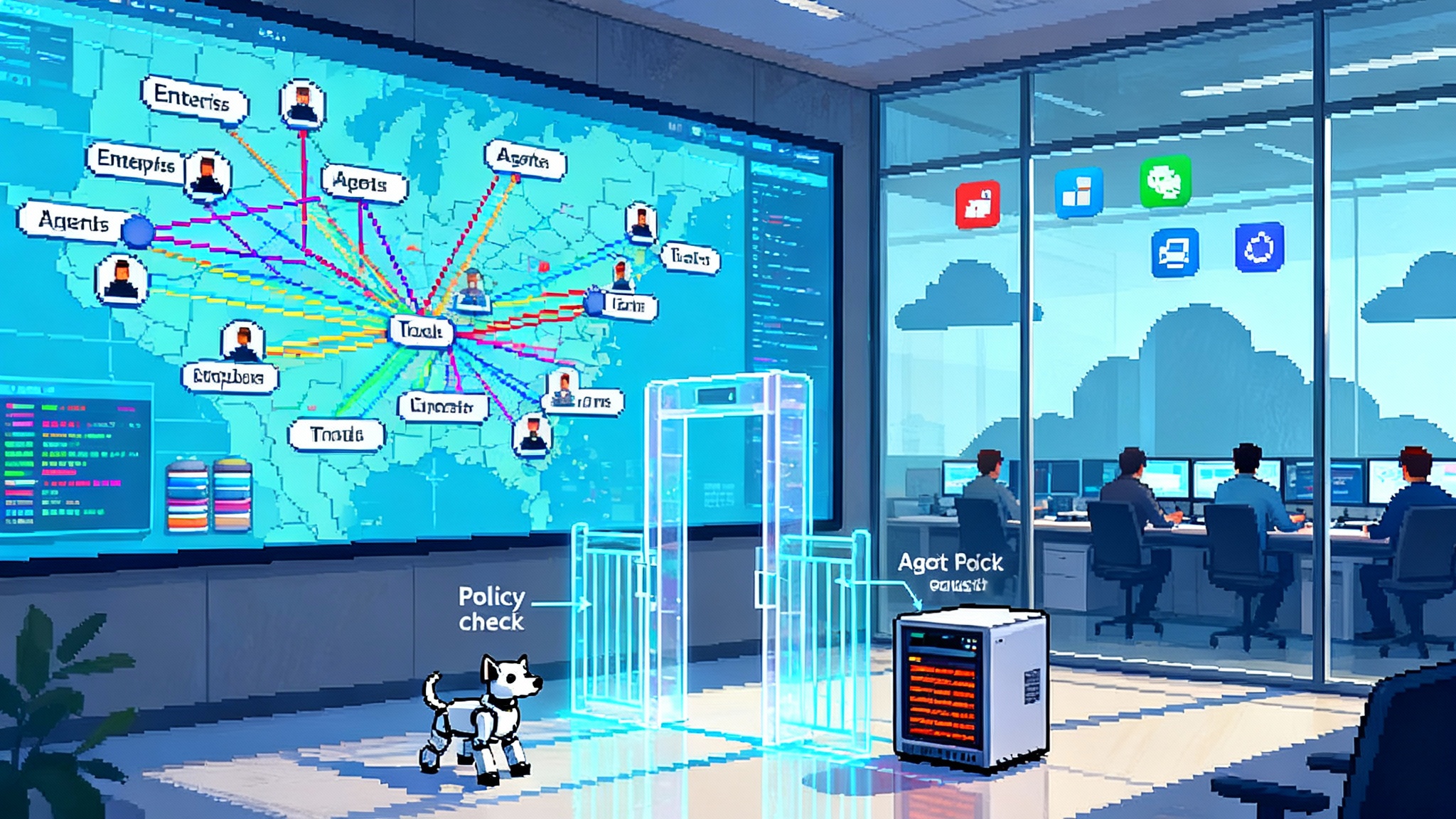
The second shoe: agents that collaborate and know your files
In August 2025, Zapier added two capabilities that complete the runtime picture: agent-to-agent calling and live knowledge connectors. In plain terms, agents can now call each other to hand off work, and they can consult up-to-date documents from sources like Box, Dropbox, and Google Drive. Your Prospect Research Agent can enrich a lead, then call a Deal Desk Agent to generate a quote, which calls a Finance Agent to validate terms against your latest pricing file, all inside the same system. See the Zapier August 2025 release.
If pods are like departments, agent-to-agent calling is the hallway where teammates pass the folder to the next specialist. Live knowledge is the intranet library that always has the current playbook.
Why this is an inflection point for small and medium sized businesses
The hard part of agents is not intelligence. It is orchestration. A single brilliant assistant is helpful. A team of average assistants that never forget, never miss handoffs, and never stop at 5 p.m. will change your cost structure. The combination of pods, handoffs, and live knowledge turns Zapier into a practical venue for that team.
Key claim: no-code orchestration will outpace code-first agent frameworks for small and medium sized business process automation over the next few cycles. Not because code is inferior, but because the bottlenecks for smaller companies are different.
- Time to value beats theoretical flexibility: a business owner or operations lead can ship a working pod in hours. Code-first frameworks shine on custom logic and exotic integrations. Most SMBs need reliable, explainable, observable paths through common software.
- Built-in integrations beat one-off glue: Zapier’s library reduces dependency on custom middleware. Each new bespoke integration adds maintenance and security surface area.
- Governance by default: non-developers get activity logs, role-based access, and run history without standing up a stack of observability tools. That matters when you have two admins, not an IT department. For deeper controls, see our agent security stack guidance.
- Labor economics: most SMBs do not employ machine learning engineers. They do have operations managers who understand their processes intimately. No-code turns that tacit knowledge into maintainable artifacts.
Put differently: if you are building avionics, you want code-first control. If you are moving leads from web form to booked meeting, you want a system your operations person can edit at 8 a.m. without a pull request.
Reliability and governance: the real trade-offs
Let us be precise about trade-offs, because reliability and control determine whether these systems leave the pilot stage.
- Determinism versus adaptability: a scripted workflow is predictable but brittle. An agent with context can handle messy inputs but may make novel choices. The new model encourages a hybrid: give each agent a narrow job, then use pods and handoffs for overall flexibility while keeping each piece testable.
- Observability versus noise: logging every action helps audits but can drown teams in alerts. The All activity view centralizes events. The discipline is to tag events with business-level labels like lead_id, order_id, and customer_tier so exceptions route to the right person.
- Cost control versus throughput: models that reason on long documents can run up token bills. Live knowledge reduces repeated context stuffing, but you still need rate limits and per-pod budgets. Set a spend cap and a daily action limit for each pod that matches its economic value.
- Access and data scope: connecting files is powerful and risky. Start with read-only credentials and least-privilege folders. Mask or omit personal data unless absolutely required. Put a human step on any action that crosses a risk threshold, like deleting data or issuing refunds.
A useful metaphor is a restaurant kitchen. You want every station to have its pantry, tools, and a clear remit, plus a pass that controls what leaves the kitchen. You do not want a single chef improvising the whole menu during service.
The automation math: why no-code wins at the margin
- A code-first agent project needs a developer, a repository, a deployment pipeline, a knowledge store, observability, and credentials infrastructure. Even with a good template, that is weeks to first value.
- A no-code agent pod starts with built-in app connections, run logs, credential vault, and a builder that an operations lead can use. With Copilot-style assistance, the path from idea to running agent is shorter and the work stays close to the process owner.
The winner is not the platform with the most features. It is the one that turns backlogged Standard Operating Procedures into running software fastest, then keeps them current without depending on a single developer’s calendar.
Architecture in practice: pods as microservices, handoffs as message queues
If you squint at the new shape, you will recognize familiar patterns from software architecture:
- Treat each agent like a tiny service with a single responsibility. The service owns its inputs, outputs, and error states.
- Treat a pod like a bounded context with a clear business objective such as first-touch sales or invoice reconciliation.
- Use agent-to-agent calls like a message queue. Pass compact, structured payloads rather than entire documents when handing off.
- Keep state in your systems of record. Agents should read and write to CRM, ERP, accounting, or databases rather than hoarding context in prompts.
This view helps non-technical teams adopt engineering discipline without writing code. It also clarifies where to put guardrails: at the pod boundary.
A 90-day playbook to pilot multi-agent workflows
Below is a pragmatic plan that an SMB can follow without hiring a new team. Goal: prove value, manage risk, and document what it would take to scale.
Days 0 to 30: identify a thin slice and set guardrails
- Pick one process that repeats daily, touches at least two apps, and has a clear success metric. Examples: lead qualification to meeting booked, ticket triage to resolution category, invoice intake to approval queue.
- Define a single pod with two to three agents, each with one job. Write the job in one sentence, for example, Qualify leads and tag intent or Draft a personalized reply from the knowledge base.
- Connect live knowledge to only what you need. Attach a single folder such as Pricing and Packaging or Onboarding Playbooks. Use read-only access.
- Instrument from day one. Add fields that stamp a run_id, customer_id, and the agent name on every record the pod touches. Decide where you will read success data from: calendar events created, tickets resolved, invoices approved.
- Create an exception lane. Build a human-in-the-loop step for anything that changes money, deletes records, sends bulk messages, or modifies permissions.
- Set budgets and rate limits. Decide a daily action cap per agent and a monthly token spend cap if applicable. Alert when you hit 80 percent of either.
- Success by day 30: a working pod that touches real data, produces a weekly run report, and has at least one human approval step.
Days 31 to 60: expand the flow and measure lift
- Add agent-to-agent handoffs for the highest friction transition in the process. For example, after a lead is qualified, an enrichment agent fetches firmographics and hands off to a routing agent.
- Broaden live knowledge modestly. Add a second folder such as Case Studies or Product Sheets. Tag every file with freshness dates in filenames to spot stale inputs.
- Introduce a feedback loop. For every exception an agent raises, require the operator to choose one label: missing context, unclear instruction, or tool failure. Review weekly and fix the top two issues.
- Ship a dashboard. Show the three numbers that matter: volume processed, success rate, time saved per item. If you do not know time saved, measure a baseline with ten manual runs.
- Start negative testing. Create dummy records that should be rejected and confirm the agents do not act. Log and fix any false positives.
- Success by day 60: handoffs are working, two knowledge sources live, a basic dashboard exists, and the false positive rate is under a threshold such as 2 percent.
Days 61 to 90: harden, templatize, and decide to scale
- Harden the pod boundary. Require approval for cross-pod effects such as creating a new customer, sending bulk emails, changing pricing, or issuing refunds.
- Write runbooks. One page per agent: purpose, inputs, outputs, failure modes, and who owns it.
- Templatize your best agent. Turn it into a reusable pattern others can clone with minimal edits.
- Model the economics. Combine volume and time saved to estimate reclaimed hours. Multiply by a conservative fully loaded hourly cost. Subtract software and token spend to get month-one payback.
- Decide to scale or stop. If payback is positive and the exception load is manageable, add the next adjacent agent. If not, prune. Do not expand a pod that still needs babysitting.
- Success by day 90: a defensible business case, documentation, and a packaged agent template you can reuse.
Practical design patterns you can copy tomorrow
- Handoff with receipt: when Agent A calls Agent B, require B to write a summary field back to a shared record for traceability.
- Freshness check: store a last_updated date on every knowledge file and have agents refuse to act if it is older than your standard.
- Approval triangles: no single agent can both propose and send into two agents with a human approval in between. Split propose and send into two agents with a human approval in between.
- Structured payloads: pass compact fields such as purpose, target_id, and next_action rather than paragraphs of text.
- Reset to defaults: if an agent fails twice in a row on the same record, send it back to a human and flag the owner. Two attempts are sufficient before escalation in most SMB flows.
Where code-first still shines, and how to integrate it sensibly
There are cases where a code-first framework is the right tool: complex custom models, proprietary algorithms, heavy data science, or hard performance constraints. Rule of thumb: if the business logic is your secret sauce, keep it in code. If the business logic is a translation between well known apps and documents, no-code will outrun it.
If you must blend both worlds, use Zapier agents to orchestrate and call your custom services at the edges. Treat your code as a specialized tool that a pod can invoke. Keep the heavy lifting in your service, but let the no-code runtime handle triggers, handoffs, logging, and approvals.
What this means for the next year
The center of gravity for SMB automation is moving from chat to orchestration. The workflows that move revenue, fulfill orders, and keep support queues healthy are mostly sequences of small steps, each with a clear purpose. Zapier’s multi-agent upgrade aligns with that shape. Pods mirror teams. Agent-to-agent calling mirrors handoffs. Live knowledge mirrors the shared drive and its ever-changing documents. And as voice interfaces mature, expect adjacent shifts like voice agents as runtime.
The bottom line
Your first multi-agent win will not be flashy. It will be a quiet fix to a daily annoyance that removes dozens of minutes a day. Lean into that. Use the 90-day plan to build confidence and muscle. Keep each agent boring and reliable. Then let pods and handoffs carry complexity for you.
The shift is clear: automation platforms are turning into the agent runtime. For SMBs, that is good news. It means the people who know the work can finally run the software that runs the work.