Google puts AgentOps on stage with self-healing and observability
Google just shifted Vertex AI Agent Builder from ‘build a demo’ to ‘run a service.’ Self-healing, trace-first observability, and policy controls move AgentOps to the center of enterprise roadmaps.

Breaking: AgentOps is no longer a side project
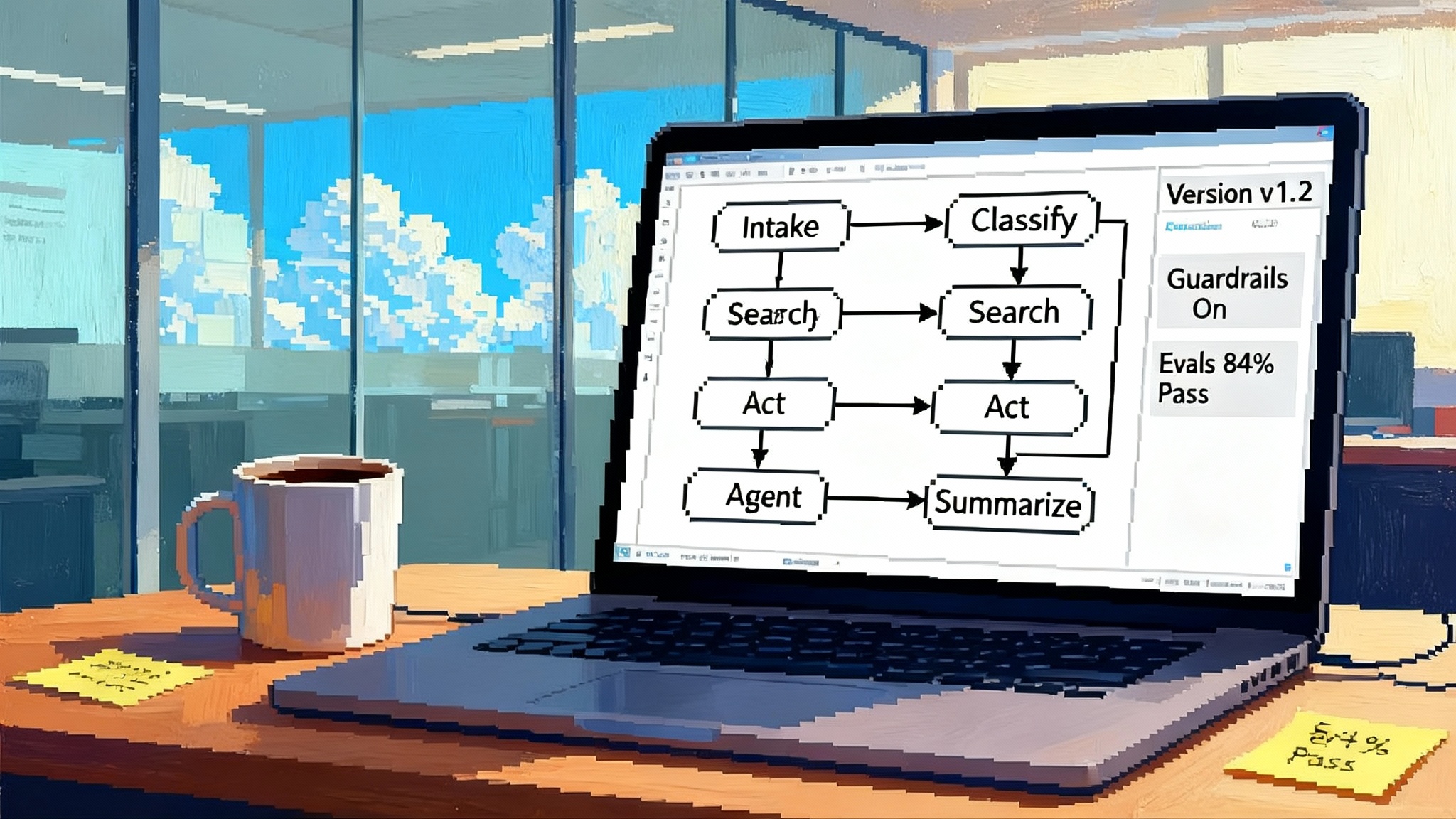
Google just turned up the lights on production-grade agent operations. In new updates to Vertex AI Agent Builder reported this week, Google added a self-heal plugin, a testing playground, traces, and richer dashboards for token usage, latency, and tool calls. In short, the emphasis moved from build an agent to run, observe, and auto-remediate. That is a notable shift, because most enterprise teams already know how to prototype an agent. What blocks scale is keeping that agent reliable in the messy reality of live systems. The new capabilities, including Model Armor integrations and tighter governance, are a direct answer to that reality. For a concise overview of the additions and how Google is framing them, see TechRadar on Agent Builder upgrades.
Compare the shift from prototype to production with how others have matured their stacks, including production grade agents with AgentKit.
From “build an agent” to “run, observe, auto-remediate”
In 2023 and 2024, the energy was on prompts, tools, and demos. By late 2025, the bottleneck is operations. If you think of agents as a new kind of microservice, the lesson is familiar. You do not ship a microservice without logs, traces, budgets, retries, and policies. Agents need the same operational scaffolding, plus a few agent-specific controls.
Self-healing is the headline because it converts intermittent failure into graceful degradation. In practical terms, self-healing is not magic. It is a set of strategies your agent can execute when the happy path breaks. The useful idea is that these strategies are now packaged and observable, rather than bespoke scripts hidden in notebooks.
What self-healing really means in production
Here is a simple example. Your fulfillment agent calls an inventory API, gets a 502, and stalls. A self-heal routine can try a structured backoff and retry. If that fails, it switches to a cached index; if that misses, it reformulates the tool call with a smaller query slice; if that still fails, it degrades the user experience to a human-handoff with context preserved. The important part is not the number of retries. It is that you capture each branch as a traceable span, tag the outcome, and feed it to your dashboards. Now you can see the rate of tool-call failures, the cost of fallbacks, and whether users reached a useful endpoint.
Other self-healing patterns you will want on day one:
- Plan repair: When a subtask fails, the agent prunes or rewrites only the relevant step instead of restarting the entire workflow.
- Tool substitution: If Tool A is down, route to Tool B that honors the same schema. For critical paths, keep a static backup plan that uses a reduced capability version of the tool.
- Model fallback: Use a smaller, faster model to quickly classify failure modes and choose the best repair path before invoking a larger model.
- Guarded execution: Add schema validation and policy gates before tool calls. If an argument is out of bounds, fix it or shift to a safer preset.
None of this eliminates failure. It turns failure into a first-class, measurable feature of the system. That is the difference between a demo and a dependable service.
The AgentOps stack is consolidating
Across platforms, you can see a common set of layers emerging. Think of them as the rack units in a data center cabinet for agent operations.
- Testing playgrounds
- What it is: An interactive bench where teams can seed prompts, upload fixtures, and run multi-turn scripts against a staged or production-like agent.
- Why it matters: You learn where the agent bends before production does. Better still, you snap the bench into your continuous integration so every change runs through the same gauntlet.
- Google’s move: A dedicated playground anchored to the Agent Development Kit, with traces attached so you can jump from a failed test right into the step-by-step execution.
- Traces you can trust
- What it is: Span-level visibility of the agent’s plan, tool calls, retries, and guardrails fired. Useful traces tell you what the agent believed, what it did, and why.
- Why it matters: If you cannot see the chain of thought and action, you cannot debug cost spikes, latency cliffs, or erroneous tool calls.
- Google’s move: A traces tab with Cloud Trace integration that maps the agent’s timeline from user request to final action. You can filter by tool, model, latency, or error code.
- Cost and latency dashboards
- What it is: Real-time and historical charts for tokens, tool-call counts, success rates, and time to respond across scenarios.
- Why it matters: Operations leaders need a budget and a speedometer. Both are provided by token and latency telemetry, broken down by step.
- Google’s move: Prebuilt dashboards for token usage and error breakdowns, plus agent-level metrics that roll up across versions.
- Model armor and policy controls
- What it is: Inline enforcement for prompt injection, data loss prevention, and brand safety. Policies run before and after model calls and tool execution.
- Why it matters: You do not scale without governance. The discipline is to codify rules once and enforce them across all agent paths.
- Google’s move: Model Armor integrated with Vertex AI and Agentspace so prompts and responses are screened centrally. You get consistent enforcement plus logs that show which policies triggered. For broader context on safety programs, see the agent security stack.
- Tool governance and identity
- What it is: Clear identity for agents and rules for what they can touch. Each tool call should carry an actor, a purpose, and a scope.
- Why it matters: Least privilege and traceability reduce risk and speed audits. If an agent acts on behalf of a user, you need proof.
- Google’s move: Tighter identity controls in Agent Engine and policy hooks that validate parameters before hitting sensitive systems.
- Memory, retrieval, and context budgets
- What it is: Structured short-term and long-term memory, plus guardrails on how much context to keep and why.
- Why it matters: Memory is a cost and a liability if it is not governed. Good AgentOps defines what to remember, for how long, and under what legal basis.
- Google’s move: Memory patterns and retrieval building blocks that respect budgets and are visible in traces.
A 2025 benchmark: Google vs AWS vs OutSystems
Here is a pragmatic look at where the big stacks stand right now.
-
Runtime and isolation
- Google: Agent Engine focuses on managed deployment with per-session tracing and policy gates. Long-running tasks and multi-step orchestration are first-class citizens.
- AWS: Bedrock AgentCore highlights complete session isolation and support for long-running workloads up to eight hours, which matters for back office processes and complex automations. See the latest in the AWS Bedrock AgentCore capabilities overview.
- OutSystems: Agent Workbench brings a low-code canvas on top of enterprise systems to coordinate agent tasks from day one, designed to fit into existing app delivery teams.
-
Tool integration and gateways
- Google: Broad connector coverage, Apigee for APIs, plus support for Model Context Protocol so agents can discover and use tools without hand-coded glue.
- AWS: AgentCore Gateway can transform existing APIs and Lambda functions into agent-ready tools and connect to Model Context Protocol servers. That shortens the path from enterprise services to agent actions.
- OutSystems: Uses the platform’s integration catalog and governance to wire agents into core workflows with familiar low-code patterns.
-
Observability and traces
- Google: Traces and dashboards flow into Cloud Trace and Cloud Monitoring. You can filter by tool, span, or error to isolate the cause within minutes.
- AWS: AgentCore Observability pushes runtime and tool telemetry into Amazon CloudWatch, and it is OpenTelemetry compatible so teams can forward data to providers like Datadog or Langfuse. That compatibility is valuable for enterprises with an existing observability estate.
- OutSystems: Focuses on end-to-end flow visibility within the platform, giving app teams a single pane of glass for business and agent metrics.
-
Self-healing strategies
- Google: Exposes self-heal behaviors as configurable plugins and patterns. The win is that these actions show up in traces, so you can treat them like code and tune them over time. This is detailed in TechRadar on Agent Builder upgrades.
- AWS: Provides the building blocks for retries, backoff, and fallback through orchestration and tool patterns. Combined with observability, teams can script robust auto-remediation.
- OutSystems: Bakes remediation into low-code flows, with explicit branches for retries, policy failures, and human handoffs.
-
Governance and safety
- Google: Model Armor and Security Command Center bring central policy management for prompts, responses, and agent interactions, which is crucial for regulated workloads.
- AWS: Identity-aware authorization with native integration to enterprise identity providers plus compatibility with third-party observability and guardrail tools.
- OutSystems: Leans on the platform’s governance model with role-based access and change management that many enterprise app teams already use.
The shared direction is unmistakable. All three vendors are investing in the same operational primitives. The differentiation is speed to implement inside your current stack and how deeply each platform integrates with your observability and security systems.
Why this consolidation matters now
Two forces are driving consolidation around production tooling. First, procurement is done paying for prototypes that cannot pass an audit or sustain a week of production traffic. Second, agent interoperability is improving. Protocols such as Model Context Protocol and agent-to-agent conventions lower the cost of switching frameworks. When operational layers are standardized and your agents can talk to each other, the risk of vendor lock-in falls. For a Google-centric view of how productivity platforms will host agents, see Workspace as an agent OS.
A pragmatic KPI playbook for AgentOps
If you manage an agent program, you need a scoreboard that operations, security, and product can all read the same way. Start with these metrics.
-
Task Success Rate
Definition: Percentage of agent sessions that achieve the user’s intended outcome without manual intervention.
How to measure: Use traces to tag the final span with outcome labels such as resolved, escalated, abandoned, policy blocked. Success is resolved.
Target: Greater than 85 percent for narrow tasks; 60 to 75 percent for complex multi-step flows in early production, rising with iteration. -
Tool-call Accuracy
Definition: Percentage of tool invocations that have valid parameters and produce the expected class of result on first attempt.
How to measure: Add schema validators before tool calls and log pass or fail. Compare tool response class to a gold standard for a sample set.
Target: Greater than 95 percent for critical tools. Add automated rollback if accuracy dips for two consecutive deploys. -
Containment Rate
Definition: Percentage of sessions resolved by the agent without handoff to a human.
How to measure: Instrument your handoff endpoint and correlate with session traces. Subtract policy blocks that intentionally require human review to avoid punishing good governance.
Target: Depends on risk. In support, 60 to 80 percent is realistic when the agent has action authority and well-tuned retrieval. -
Mean Time To Acknowledge and Mean Time To Repair
Definition: MTTA is time from incident detection to triage start. MTTR is time from detection to mitigation or fix.
How to measure: Create alerts from error spikes, tool outage events, or policy block anomalies. Track the first triage note and the deploy or config change that remedied the issue.
Target: Sub 5 minutes MTTA and under 30 minutes MTTR for P1 issues once observability is in place.
Implementation tips:
- Tag every span with user intent, tool name, retry count, and policy decisions. This makes dashboards useful without manual data wrangling.
- Set token budgets per workflow and alert on deviations greater than 20 percent week over week.
- Run nightly canary tests on your top 20 flows and fail the build if containment drops more than 5 points.
A rubric to spot real agents vs agent-washing
You can spot a real agent in five minutes if you know what to look for.
- Tool authority: The agent can take action through at least one production system with parameter validation. Demos that only chat without tools do not qualify.
- Multi-step plans: The agent executes multi-step workflows and shows its plan in traces. Single-step wrappers around a model are not agents.
- Memory with rules: There is an explicit memory or retrieval strategy with retention limits and deletion policies. If all context is ad hoc, it will not scale.
- Observable behaviors: You can open a trace and see spans for plan, tool calls, retries, and policy gates. If you cannot see it, you cannot trust it.
- Self-healing paths: There are documented fallbacks and you can trigger them in a test. If the agent only works on the happy path, it is not production ready.
- Policy enforcement: There is an inline guardrail layer screening prompts and responses, with logs to prove it. Screenshots of annotation tools are not governance.
- Identity and audit: Every tool call carries agent identity, user identity when applicable, and purpose tags. If you cannot answer who did what and why, you are not ready for an audit.
- SLOs and budgets: There are service level objectives for latency, accuracy, and cost. If no one owns the budget, the pilot will stall.
- Versioning and rollback: You can roll back an agent version without redeploying infrastructure. If production changes require notebook edits, stop.
- Human-in-the-loop: There is a safe escalation path with context preserved. Real agents coexist with humans.
If more than three of these are missing, you are looking at agent-washing. Treat it as a prototype, not a product.
What to do on Monday
- Pick one narrow, high-volume workflow such as refund approvals or knowledge triage.
- Instrument everything. Add tracing, parameter validation, and policy gates before any tool call.
- Define the four KPIs above and baseline them with a one-week shadow run. Set hard alerts for spikes.
- Add at least two self-heal strategies. Start with simple retry and a cached fallback. Log the outcome of both.
- Run a brownout test by temporarily increasing tool error rates in staging. Verify that your containment and MTTR do not collapse.
- Socialize the dashboards with your support, security, and finance partners. Agree on budgets and escalation paths before you scale traffic.
Why this unlocks enterprise scale in 2026
Enterprises scale systems they can see, control, and fix. The combination of self-healing, deep observability, and centralized policy control turns agents from experiments into services. You get higher containment without hiding risk, cost curves you can explain to finance, and audit trails that satisfy compliance. As vendors converge on the same AgentOps layers and protocols make agents interoperable, you can invest with confidence. The winners in 2026 will not be those who built the flashiest agent. They will be the teams that run agents like any other tier-one service: observable, governed, and capable of fixing themselves before users notice.
That is the real headline behind Google’s latest move. AgentOps is center stage now, and the next act is scale.