Mistral AI Studio brings a sovereign Agent Runtime to Europe
Mistral unveiled AI Studio with a Temporal-backed Agent Runtime, deep observability, and hybrid or on-prem deployment. It gives regulated European teams a credible, sovereign path to production agents today.

Breaking: Europe gets a production-grade Agent Runtime
On October 24, 2025, Mistral announced AI Studio, a production platform that combines an Agent Runtime built on Temporal, built-in observability, and hybrid or on-prem deployment options. The promise is simple. Move enterprise agents from demos to dependable systems that are auditable, measurable, and compliant with European data residency. If your teams are stuck in pilot purgatory, this is the strongest sovereign push to date for getting agents into real operations. See the Mistral AI Studio launch details.
Why this matters now
Over the past year, many European enterprises have built proof-of-concept copilots and retrieval augmented generation assistants. Most never reached scale for three reasons.
- No durable execution. Multi-step agents fail mid-flight and cannot replay reliably.
- Thin observability. Teams cannot see where quality regresses, which prompts drift, or why a run went off the rails.
- Governance gaps. Security, audit trails, and data residency are bolted on at the end rather than designed in.
AI Studio targets those pain points by making execution, measurement, and governance first-class parts of the platform. The pitch does not hinge on a single benchmark. It hinges on the operational spine that turns AI into an accountable system.
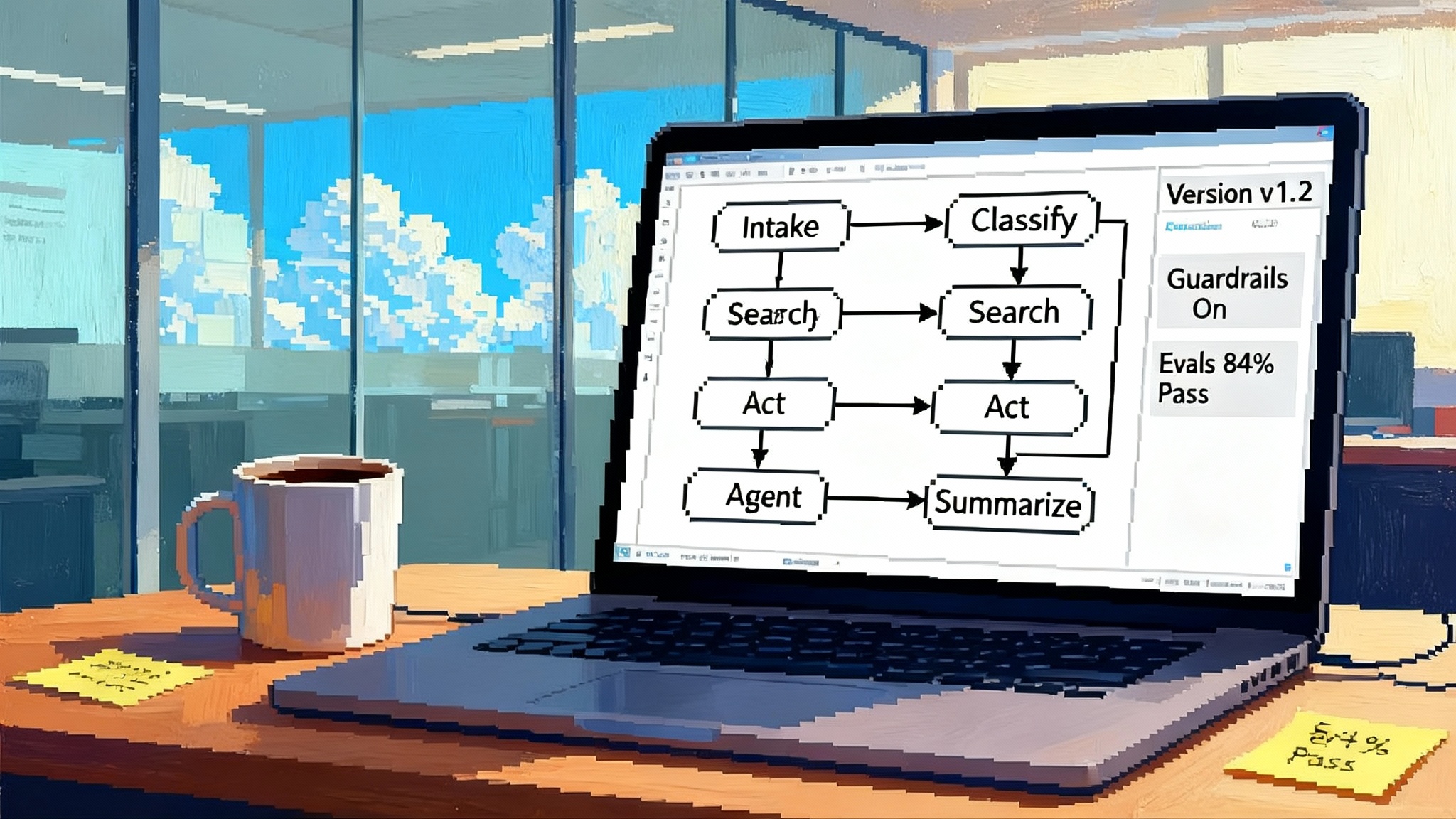
What the Agent Runtime actually is
Think of the Agent Runtime as air traffic control for your agents. It coordinates every takeoff and landing across a complex sky of tools, data stores, and human approvals. Where a typical prototype chains a few function calls and hopes for the best, the Agent Runtime turns each run into a stateful, recoverable workflow.
The practical benefits:
- Long-running, multi-step flows. A claim intake that pauses for human review today and resumes tomorrow without losing context.
- Automatic retries with rules. Transient network issues do not become production incidents.
- Deterministic replays. You can step back through time and reproduce exactly what happened and why.
- Auditable graphs. Every execution path is visible, which is essential for risk, quality, and post-incident analysis.
Temporal is the backbone
Under the hood, Mistral’s Agent Runtime uses Temporal, a durable execution engine that treats workflows as code and guarantees progress even when infrastructure fails. If a worker crashes or a region blips, the workflow resumes from the precise point it stopped. That design makes multi-step agents feel less like clever scripts and more like real systems that are safe to operate. For readers new to this concept, see the Temporal platform overview.
For enterprise engineers, this choice is significant. Temporal brings a decade of proven patterns such as deterministic workflows, activities with automatic retry and backoff, heartbeats for long tasks, and a complete event history for every run. It also supports self-hosting and Temporal Cloud, which lines up with AI Studio’s hybrid story.
Observability is built in
AI systems fail quietly if you cannot see them. AI Studio’s observability closes that gap by turning raw traffic into structured data you can evaluate.
- Explorer for traffic slicing. Filter by prompt, model version, tool path, or customer segment to find regressions.
- Judges as reusable evaluators. Encode quality rules and scoring logic, then apply them at scale across new versions.
- Datasets and campaigns. Convert real interactions into curated evaluation sets and run them continuously.
- Dashboards and iterations. Track quality, cost, and latency over time, not as one-off experiments.
If this is your priority area, compare with our AgentOps observability playbook to see how leaders are converging on similar telemetry.
RAG becomes measurable and governable
Retrieval augmented generation succeeds or fails on data quality and retrieval fidelity. AI Studio’s primitives make RAG a measured practice rather than a hopeful add-on.
- Telemetry at every hop. Log the query, retrieved chunks, and their sources. Attach the scoring from your judge. Keep the chain of custody.
- Evaluation as code. Define retrieval precision and recall, groundedness, citation coverage, and answer faithfulness. Run those checks on every new index build or embedding change.
- Reproducible runs. When incidents happen, replay the exact run with the same documents and model version. Prove whether the failure came from retrieval, generation, or a tool call.
In practical terms, RAG becomes a first-class capability you can certify, not just a pattern you demo.
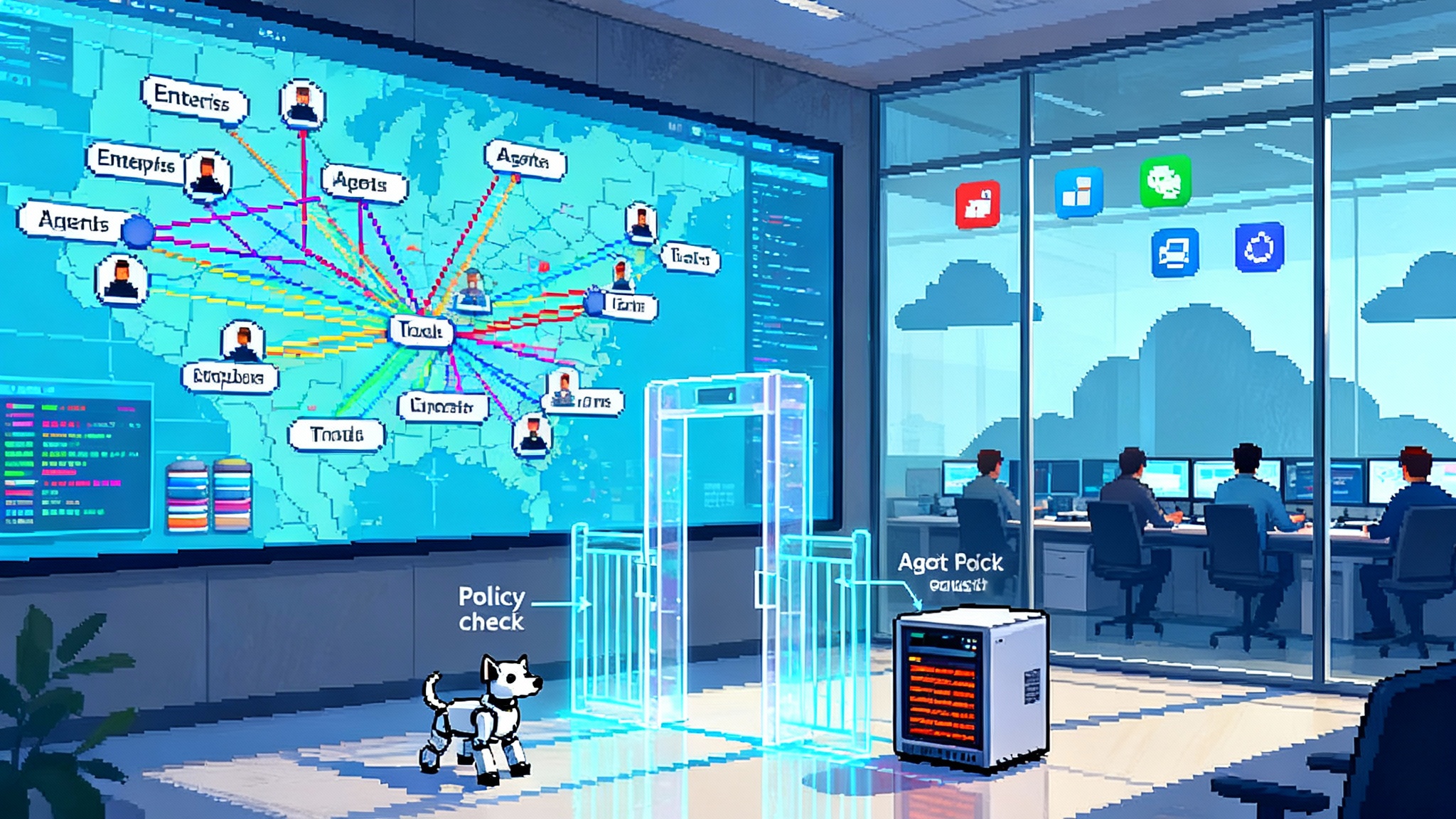
Sovereign by design: hybrid and on-prem options
For banks, insurers, healthcare providers, utilities, and public sector bodies, the platform’s deployment options are the headline. You can run the Agent Runtime close to your systems with choices that include virtual private cloud, dedicated environments, or self-hosted setups. That makes strict data residency and separation achievable without redesigning the application. It also creates a path to air-gapped or restricted-network environments where managed multi-tenant services are not an option.
The difference is control. You decide where the data plane runs, who can access logs, and how models are versioned and pinned. That control is what risk and compliance teams mean by sovereignty.
How it contrasts with U.S. cloud-first stacks
Leading platforms in the United States have optimized for elastic, managed services. That is a great fit for fast-moving software teams who can ship to public cloud regions. It is a hard fit for regulated workloads that require self-hosted agents, strict network boundaries, or on-prem orchestration without cross-border data movement. For a contrast on the U.S. side, see OpenAI AgentKit production agents.
Mistral’s stack makes the opposite trade. It tries to preserve the ergonomics of a modern platform while letting enterprises keep physical control of execution and telemetry. Portability matters here. If your agent logic is a Temporal workflow and your evaluation harness runs in your environment, you can change models, modify tools, and even switch clouds with less rework.
What the architecture unlocks
- Auditable multi-step workflows. Each run emits a static graph and event history. Post-incident analysis becomes a replay, not a blame session.
- Measurable quality. Judges turn subjective feedback into metrics you can gate on. If groundedness drops below target, you stop promotion.
- Safer iteration. A staging environment with production-like telemetry lets you experiment, evaluate, and promote with clear evidence.
- Vendor flexibility. The runtime is not married to one model vendor. You can mix open weights, hosted models, and fine-tunes while keeping a single control plane.
A 90-day pilot plan for regulated teams
You do not need a moonshot to validate value. Pick one process with frequent handoffs, partial automation, and high documentation burden. Two examples work well: claims intake for insurance or policy research for banking compliance.
Days 0 to 30: define and instrument
- Problem framing. Choose one process where a 20 percent cycle-time reduction would matter. Map steps, systems, and handoffs.
- Data governance. Classify inputs and outputs. Define what can leave your network, what must stay, and who sees telemetry.
- Evaluation design. Encode success as metrics. Start with retrieval precision and recall, groundedness, citation coverage, task success rate, p95 latency, and cost per task.
- Golden sets. Build a 200 to 500 item evaluation dataset from real cases with clear expected answers and allowed sources.
- Runtime foundation. Deploy the Agent Runtime in a non-production environment close to your systems. Integrate single sign-on, logging, and secrets management.
- Observability wiring. Route all runs into the Explorer. Set up judges for groundedness and policy compliance. Create dashboards for quality, cost, and latency.
Deliverables: a one-page charter, an architecture diagram, evaluation spec, and a working skeleton workflow that passes health checks.
Days 31 to 60: build the agent and harden it
- RAG pipeline. Connect your document stores. Add indexing, chunking, and reranking. Log retrieved snippets and their sources.
- Tools and human-in-the-loop. Add connectors for case systems, knowledge bases, and approval queues. Insert human checkpoints where required by policy.
- Deterministic workflows. Encode each step as a Temporal workflow with explicit retries and backoff. Include compensating actions for partial failures.
- Safety gates. Block promotion if judges detect hallucinations or missing citations above threshold. Add automated red teaming for sensitive prompts.
- Offline evaluation. Run campaigns on your golden sets after every change. Track trend lines for quality and latency.
Deliverables: a feature-complete agent behind access control, dashboards showing week-over-week improvement, and a runbook for incidents.
Days 61 to 90: pilot with real users
- Limited rollout. Invite 50 to 100 real users. Keep a hotline back to the team. Collect structured feedback inside the product.
- Chaos and replay drills. Kill workers, simulate timeouts, and prove that workflows resume cleanly. Use replays to validate determinism.
- Business experiments. A and B test prompt variants and tool paths. Tie results to resolution time, first contact resolution, and net promoter score for internal users.
- Compliance pack. Ship the audit story. Include data flow diagrams, access controls, judge definitions, and sample replays.
- Go or no-go. Compare pilot KPIs against targets. If you hit two or more, prepare a production migration plan with a clear rollback path.
Deliverables: a pilot report with charts, a compliance appendix, and a prioritized backlog for productionization.
KPIs that prove impact
Quality and safety
- Groundedness score. Target 0.9 or higher on judge-scored answers. A low score blocks promotion.
- Retrieval precision and recall. Precision above 0.8, recall above 0.7 on golden sets. Investigate drift weekly.
- Hallucination rate. Keep below 1 percent on judged samples. Any spike triggers a rollback.
- Citation coverage. Over 95 percent of answers with at least one verifiable source.
Operations
- p95 end-to-end latency. Under 3 seconds for interactive tasks, under 15 seconds for heavy retrieval.
- Autonomy rate. At least 60 percent of tasks completed without human escalation by day 90.
- Replay success rate. Over 99 percent of pilot runs are reproducible in staging.
- Incident time to recover. Under 10 minutes using Temporal resume and compensating actions.
Cost and scale
- Cost per task. Baseline and then reduce by 20 percent via caching, reranking, or model routing.
- Peak concurrency. Handle 10 times normal hour traffic without data loss during a surge test.
- Storage efficiency. Keep average retrieved context under 15 kilobytes per query without quality loss.
Compliance and governance
- Audit completeness. 100 percent of runs include event history, retrieved sources, and judge scores.
- Access adherence. Zero unauthorized access events in logs. Quarterly attestation signed by security.
- Data residency. 100 percent of production runs stay within declared regions.
How to brief your risk and compliance teams
- Start with the replay. Show that every run has an event history and can be reproduced byte for byte.
- Show judge definitions. Explain how groundedness and policy checks are encoded and enforced before promotion.
- Prove data control. Walk through where the runtime executes, who has access to logs, and how secrets are managed.
- Explain rollback. Demonstrate a safe fallback when quality drifts or a tool fails.
This shifts the conversation from abstract fear to concrete controls that auditors can inspect.
Questions to ask any vendor in this category
- Where does the data plane run by default and by exception. Can we self-host the runtime.
- Can we pin model versions and reproduce a run six months later.
- How are judges implemented. Can we bring our own evaluators and share them across teams.
- Do we get static execution graphs and event history for every run. How long is retention.
- What is the path to air-gapped or restricted-network deployments.
- How are costs surfaced per tool call, model, and step.
If the answers are vague, move on. Agents in production are operations software, not demo-ware.
A note on build versus buy
You can assemble orchestration, observability, and governance from separate parts. Many teams try, then discover they are rebuilding a platform while also trying to deliver business value. AI Studio aims to collapse that integration work. The trade is less wheel reinvention and more time on domain logic.
The signal for Europe
This launch is a marker. European enterprises can now pursue a sovereign path to production agents without giving up modern ergonomics. Alongside the momentum covered in Claude Agents expand in EMEA, the combination of a Temporal-backed runtime, evaluation-as-code, and hybrid deployment lines up with the realities of European regulation and procurement. It also creates a healthy counterweight to a world where every workload must live in a single public cloud.
The market will test whether the ergonomics and integration depth match the messaging. But the direction is right. Durable execution plus measurable quality plus governance you can audit is the formula that moves agents from novelty to necessity.
The bottom line
If you lead an AI program in a regulated organization, run a 90-day pilot now. Pick a process with real volume, wire it through AI Studio’s Agent Runtime, and instrument it with judges and replayable event history. Hold yourself to the KPIs above. The outcome will be unambiguous. Either you gain the evidence and control to scale, or you learn exactly what to fix. That is how production AI should feel: controlled, measurable, and yours.