Qwen3 Omni and Kimi K2 spark China’s open-weight reset
Two September releases compressed the agent stack from both ends. Qwen3 Omni brings real-time any-to-any speech with open weights, while Kimi K2 expands working context for code, cutting hops, failures, and cost for production-grade agents.

The September jolt that reset the stack
Two releases in September lit up developer chats and sprint planning boards. On September 22, Alibaba’s Qwen team shipped Qwen3 Omni under the Apache 2.0 license, a real time multimodal model that listens and speaks with the same brain it uses for text and vision. You can confirm the details in the Qwen3 Omni model card, including speech in and speech out, and open weights under a permissive license, which is unusual for this capability class.
Seventeen days earlier, on September 5, Moonshot AI pushed Kimi K2 0905, a long context agentic coding model that doubles its window to 256 thousand tokens and tightens tool use. Several providers added day one support, so developers could route calls through existing gateways with minimal code changes. The effect was immediate. A model that can hold a working set the size of a medium repository without elaborate retrieval changes how you design agents. This momentum mirrors how enterprises are adding talk to work capabilities, as seen when Salesforce gives AI agents a voice.
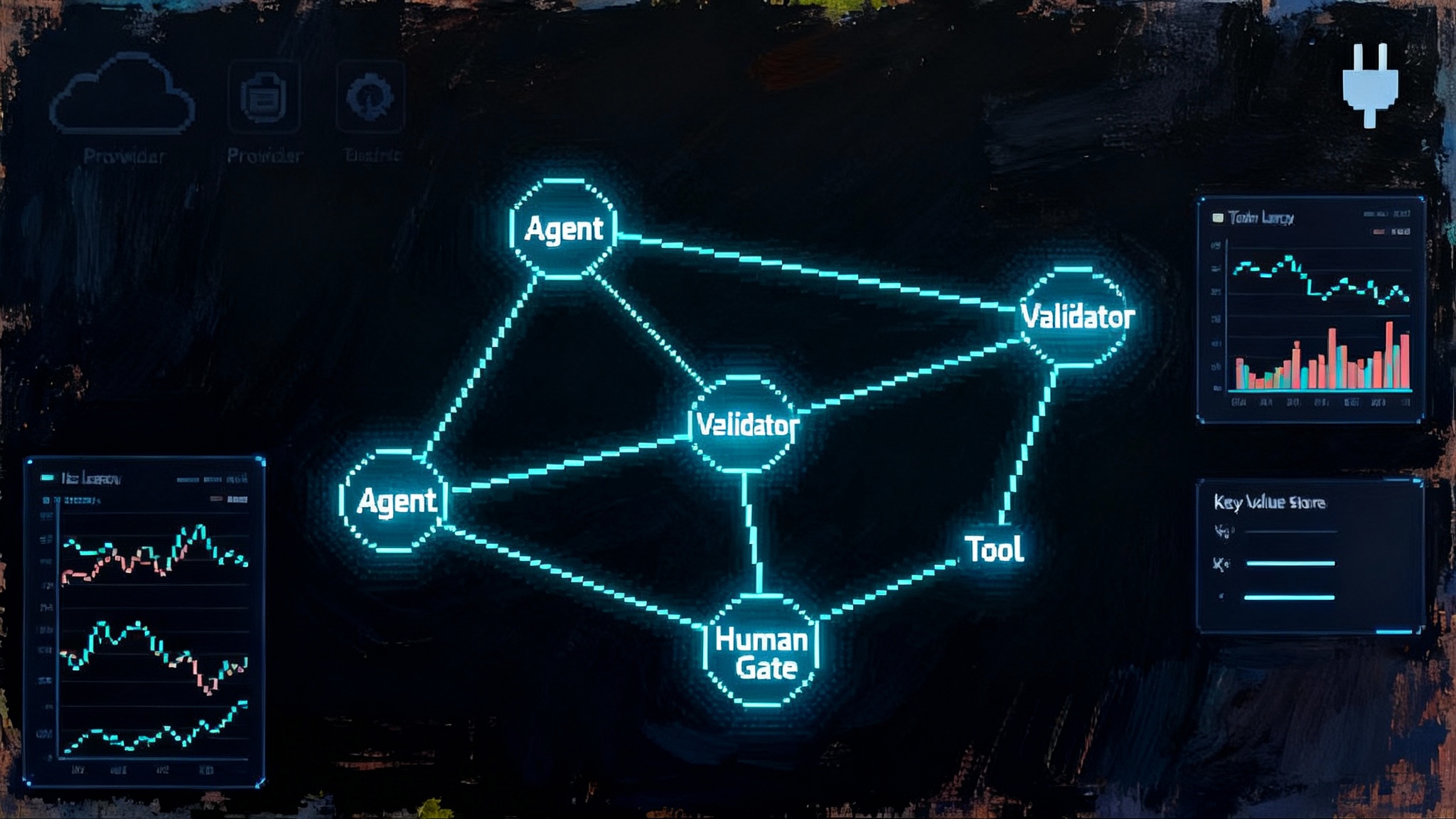
This pairing matters because it compresses agent stacks in two directions at once. Qwen3 Omni flattens the voice path, replacing a chain of automatic speech recognition, a language model, and a separate text to speech system with a single any to any model. Kimi K2 0905 flattens the code path, replacing retrieval heavy orchestration with a larger working memory that keeps more of the codebase in context. Fewer moving parts mean fewer network hops, fewer failure points, and fewer bills.
Why open weights change cost and latency
Think about the typical voice assistant of the last two years. You spoke to a microphone, audio frames streamed to a cloud speech recognizer, tokens crossed to a chat model, and the response text went to a third model to synthesize speech. That is three services, three latencies, and two transfers of sensitive audio that you might prefer stayed on your device. With Qwen3 Omni, speech in, text and tool calls, and speech out come from a single model that can run locally on a workstation or be hosted privately. The change is like replacing a three stage relay with a single solid state module.
Now consider coding agents. If your agent sees only 32 thousand tokens, you spend a lot of time deciding which files to retrieve, chunking them into windows, and hoping the right pieces land together. A 256 thousand token context moves you closer to a human working session, where the agent can read the build files, the main module, the tests, and the docs at once. Retrieval is still useful, but it is no longer the center of gravity.
Open weights magnify these wins. You can quantize for your hardware, cache prompts on your own servers, and tune system prompts and safety rules without begging a provider for a knob. You can run behind your own firewall for data residency, or burst to a provider when you need throughput. The same code path works both places, which keeps your architecture simple.
For developers who want immediate numbers on pricing and limits, Groq’s public documentation for the Kimi K2 0905 integration lists a 256 thousand token context window and per million token pricing for input and output. That gives a stable basis for cost planning and shows why long context is practical at scale. See the Groq Kimi K2 0905 docs.
What is actually new in these two models
-
Qwen3 Omni
- End to end speech, text, image, and video in one model.
- Real time streaming and natural turn taking, which matters for hands free agents.
- Open weights under Apache 2.0, with cookbooks for audio captioning, speech translation, and audio function calling.
- Early signs of a split thinker and talker design, which separates planning from speaking to keep latency low without dumbing down reasoning.
-
Kimi K2 0905
- 256 thousand token context for agentic coding and tool use.
- Stronger front end generation and more reliable tool calling, which reduces retries and glue code.
- Open weights under a Modified MIT license and native support in popular inference engines such as vLLM and SGLang.
- Broad provider availability, including speed first inference on specialized hardware and adoption in common developer gateways.
The combined effect is a reset of assumptions. Voice needs do not force a closed provider. Code agents do not require elaborate indexing peanut buttered over a tiny context window. You can pick open models, host them where you want, and still hit production level latency and quality. Many teams are aligning orchestration with the agent runtime standard with LangGraph to make these swaps safer.
Near term opportunities you can ship this quarter
These are concrete build tracks that are now unlocked or simplified. Each includes a short example and success metric.
- Private edge voice agents
- What to build: A voice agent that runs on a laptop or a small server in a clinic, factory, or call center, with speech in and speech out handled by the same model.
- How: Quantize Qwen3 Omni to 4 bit or 8 bit and run inference with vLLM on a workstation class GPU, or on a modern CPU if you can accept slightly higher latency. Use the model’s streaming interface to start speaking partial results as soon as they are ready. Add a small local wake word process to avoid sending audio when idle.
- Example: A triage assistant that turns a 12 minute intake into structured fields, asks clarifying questions, and reads back a summary for consent. All audio stays inside the network perimeter.
- Metric: Median end to end latency below 300 milliseconds between user pause and agent speech, and zero audio frames leaving the facility.
- Repo scale copilots
- What to build: A coding assistant that reads an entire service repository at once and proposes a two file refactor, a test, and a migration script in a single plan.
- How: Feed Kimi K2 0905 a sliding window of the repository up to 256 thousand tokens, plus a list of build steps as tools. Use a long running planning loop with tool results streamed back into context. Turn on strict schema for tool outputs to remove post processing.
- Example: An agent that upgrades a framework version, edits five files, runs tests, opens a pull request, and posts a change log entry. Human approval gates each high risk step.
- Metric: Median successful pull request in under 15 minutes of wall time and fewer than two retries per tool call.
- Groq and Vercel integrations
- What to build: A gateway layer that routes to Kimi K2 0905 for long context coding, to your existing fast small model for chat, and to Qwen3 Omni for voice tasks.
- How: Use a gateway that supports model aliasing. Create failover policies and token budgets by route. Turn on prompt caching for any workload with repetitive headers like repository preambles. Expose per route cost alerts so product teams can manage trade offs.
- Example: A development platform that uses Kimi K2 0905 for code reviews, Qwen3 Omni for voice pair programming, and your in house model for light chat to control costs.
- Metric: P95 latency within your service level objective and cost per pull request review below a fixed budget cap.
Execution risks and how to manage them
- License governance
- Reality: Qwen3 Omni is Apache 2.0. Kimi K2 0905 uses a Modified MIT license. Both are permissive, but you must still track obligations, provenance of any additional data you use for fine tuning, and the terms for redistribution of weights and derivatives.
- Action: Add an automated license scanner to your model registry. Store the original license text, the commit hash of the weights, and the hash of your quantized artifacts. Require a legal checklist before any model moves from staging to production.
- Evaluation and benchmark gaps
- Reality: Coding and agent benchmarks differ in harnesses and rules. One team may prune repositories or clamp tool windows. Scores are sensitive to system prompts and retry budgets.
- Action: Create an organization wide eval harness that mirrors your production constraints. Fix the tool schemas, retry counts, and context clamps. Reproduce external claims with the same harness before you switch models. Track both accuracy and wall time per task since users care about speed as much as correctness.
- Security for tool using agents
- Reality: Voice agents take untrusted audio. Code agents execute shell commands. Tool calls are an attack surface. Long context makes injection harder to spot.
- Action: Sandbox tools. Separate the planner from the executor and require schema validation for every tool result. Place a policy engine between the agent and high risk tools like database writes, email send, and cloud deployments. Red team your agent with audio based prompt injection and poisoned repository files. Log every tool call with parameters and results. For browser automations, consider a credential broker layer for browser agents.
- Privacy and data locality
- Reality: Health, finance, and enterprise data cannot always leave a region or a private network, especially audio. Even when allowed, users often prefer data to stay on device.
- Action: Support a dual mode deployment. Run Qwen3 Omni locally for audio first tasks, and keep Kimi K2 0905 on a managed cloud for heavy coding loads. Make the routing policy explicit in code so audits are straightforward.
A 90 day playbook for U.S. startups
This plan assumes a small team with product traction that wants to move fast without breaking compliance.
Weeks 1 to 2: Decide and baseline
- Pick two core jobs to be done. Example: code review improvements and a voice intake assistant for support tickets.
- Spin up a minimal eval harness. Include at least one real repository and five real audio samples per use case. Fix the tool schemas and retry counts. Log latency, token counts, and accuracy.
- Select initial models. Qwen3 Omni for voice and Kimi K2 0905 for coding are the defaults. Add your current model as a control.
- Target metrics. Example: cut code review cycle time by 30 percent and deliver sub second voice responses with no cloud audio for sensitive accounts.
Weeks 3 to 4: Prototype end to end
- Build a local voice agent. Use streaming input and streaming output. Write a small prompt to summarize each user utterance to stabilize long sessions.
- Build a repo scale code agent. Load the main service into context, plus a tool set for read, write, test, and diff. Gate every write with human approval. Keep a transcript for post mortems.
- Wire both into your gateway. Create routes by use case and set token budgets. Turn on prompt caching for repeat headers and common system prompts.
Weeks 5 to 6: Harden and measure
- Add observability. Plot cost per task, time to first token, and total wall time. Alert when a route crosses cost or latency budgets.
- Add safety. Validate tool outputs with JSON schemas. Block tools when the agent deviates from the plan. Introduce a low privilege sand box for shell commands.
- Red team the voice agent. Test audio prompt injection and nonsensical background sound. Confirm that the agent ignores instructions coming from the user’s own voice that are outside the allowed tool list.
Weeks 7 to 8: Optimize for scale
- Quantize and batch. For Qwen3 Omni, confirm that quantization does not degrade speech quality beyond acceptable thresholds. For Kimi K2 0905, experiment with chunked long prompts and keep the stable parts cached.
- Reduce retries. Tighten tool schemas and return early on non critical steps. Teach the agent to ask for a smaller goal when the plan is failing.
- Run a shadow launch. Mirror traffic from 10 percent of users, compare outcomes to your control model, and check costs.
Weeks 9 to 12: Ship and expand
- Roll out to a target segment. Small teams and opt in users first. Offer a one click rollback.
- Reduce human in the loop on narrow lanes. For example, allow the agent to update dependency files and run tests without approval, but require a human for any commit that touches business logic.
- Add a second wedge. Examples: voice based analytics summaries for managers, or agentic migrations across multiple repositories.
- Close the governance loop. Archive models, prompts, and configs for each release. Store license texts and hashes with your artifacts.
Practical design notes for teams
- Separate planning and talking. For voice, keep a quiet planner that writes text to the talker. Users will perceive a smarter agent when it is not thinking aloud.
- Use tool schemas that match your system of record. If your deployment service expects a blue green flag, make that an enum in the schema to catch errors early.
- Build a budget table per route. Put hard caps in code. If a task exceeds its budget, the agent should stop and ask a human for a smaller plan.
- Treat benchmarks as direction, not truth. Use them to pick a starting point, then tune on your own workloads.
The momentum shift
For two years, the default advice was to reach for a closed model if you needed real time voice or serious code agents. September’s releases moved the line. With open weights like Qwen3 Omni and Kimi K2 0905, developers can run private speech agents on their own machines, stretch code agents across entire repositories, and still hit production grade latency and cost targets. The hardware and hosting landscape also shifted in your favor. Specialized inference platforms claimed speed leadership while mainstream gateways added the new models to their catalogs, so you can route traffic without rewriting your stack.
This is not a story about one country beating another. It is a story about developers getting more control. Open weights give you knobs you can actually turn. Long context and real time speech give you product experiences that feel natural rather than staged.
The bottom line
Agent stacks simplify every time context grows and speech becomes native. Qwen3 Omni and Kimi K2 0905 are the latest proof. If you execute with care on licensing, evals, and security, you can ship edge voice agents and repo scale copilots in a single quarter. The window is open right now, and teams that move first will redefine what feels normal for their users by the time winter releases land.